
Hippo's data
모델 평가 - 분류(Classification) 모델 본문
학습된 모델이 얼마나 뛰어난 성능을 보이는지 평가하는 방법인 모델평가 방식은 분류(Classification)모델인지, 회귀( Regression)모델인지에 따라 다른데요
오늘은 분류(Classification)모델의 평가방법에 대해 알아보겠습니다
1. 오차/혼동 행렬(Confusion matrix)

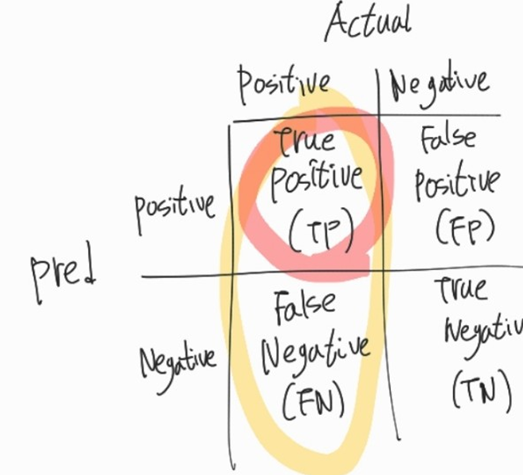
- TP (True Positive): 실제 Positive , 예측 Positive -> 실제와 예측 동일 -> 정답(True)
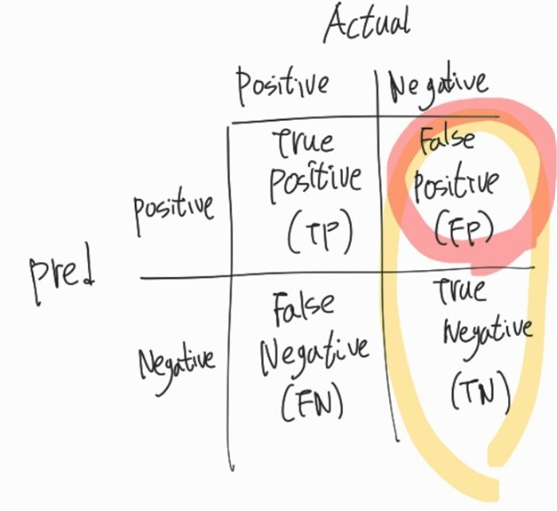
- FP (False Positive): 실제 Negative , 예측 Positive -> 실제와 예측 다름 -> 오답(False)
- FN (False Negative): 실제 Positive , 예측 Negative -> 실제와 예측 다름 -> 오답(False)
- TN (True Negative): 실제 Negative , 예측 Negative -> 실제와 예측 동일 -> 정답(True)
- Accuracy(정확도): 전체 중 정답비율
- Recall(재현율): 실제 Positive 중 예측 Positive 비율
- Precision(정밀도): 예측 Positive 중 실제 Positive 비율
- F1-score: Recall(재현율), Precision(정밀도)의 조화평균
# 일반적으로 Recall(재현율)과 Precision(정밀도)은 트레이드오프(trade-off) 관계 -> 둘을 고려한 F1-score 많이 사용됨
# 편중된 데이터는 정확도보다 F1-score가 더 효과적
-> 주어진 문제가 무엇인지에 따라 어떤 평가지표를 더 중요하게 봐야하는지 달라지므로 평가지표를 잘 설정해야 함
(재현율이 더 중요하나 정밀도가 더 중요하나, 어떤 것을 더 보수적으로 봐라봐야 하는가 등 )
2. ROC(Receiver Operating Characteristic) curve, AUC
- ROC(Receiver Operating Characteristic) curve
-> FPR(False Positive Rate)에 따른 TPR(True Positive Rate)의 변화를 그린 곡선
# FPR(False Positive Rate) -> FP/(TN + FP) -> 실제 Negative 중 예측 Positive(잘못예측) 비율 -> 낮을수록 좋음
# TPR(True Positive Rate) -> TP/(TP + FN) -> 실제 Positive 중 예측 Positive(옳게 예측) 비율 -> 높을수록 좋음
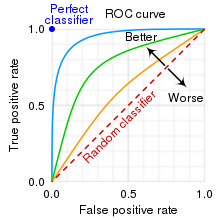
- AUC (Area Under the ROC Curve)
-> ROC 곡선 아래의 면적
-> 값이 클수록 모델 성능이 좋음
-> 최대 1(1X1, 전체면적) / 최소 0.5 (랜덤값 아래면적)
'ML(Machine Learning)' 카테고리의 다른 글
| 머신러닝 주요 모델 모델링(Scikit-learn) (0) | 2024.01.08 |
|---|---|
| 모델 평가 - 회귀(Regression) 모델 (0) | 2024.01.07 |
| 변수 선택(Feature selection) - RFE/RFE-CV/UFS (1) | 2024.01.02 |
| 스케일링(Scaling) (2) | 2024.01.02 |
| 범주형 데이터 정제하기 - 범주형 인코딩(Categorical Encoding) (0) | 2023.12.31 |

