

Hippo's data
2024 춘천 AWS DeepRacer 챔피언십 후기 본문
춘천시에서 주최한 AWS DeepRacer를 활용한 인공지능 강화학습 기반 자율주행 자동차 경진대회 후기를 남겨보겠쓥니당

https://chuncheon-deepracer.ai-castle.com/2024/
2024 춘천 AWS 딥레이서 챔피언십
본 홈페이지는 춘천시에서 개최하는 2024년 AWS DeepRacer 자율주행 인공지능 경진대회 홈페이지입니다.
chuncheon-deepracer.ai-castle.com
# AWS DeepRacer란?
Amazon Web Services(AWS)에서 제공하는 자율주행 차량 플랫폼으로 사용자가 강화 학습(Reinforcement Learning)을 사용하여 자율주행 모델을 개발하고 실습할 수 있도록 도와주는 플랫폼입니다!
사용자는 AWS가 제공하는 가상 환경에서 자율주행 모델을 훈련시키고, 실제 소형 레이싱 자동차에 적용해볼 수 있는데요
특히 상금이 걸려있는 경주 대회가 지역예선, 세계 챔피언쉽 대회도 있다고 하도라구요,, (거긴 진짜들의 리그...)
# 춘천 AWS DeepRacer 챔피언십 대회 기본 정보
저는 이번에 춘천시가 주최한 AWS DeepRacer 대회에 참가했는데욥 대회는 예선 60팀 -> 본선(20팀) -> 결선(6팀) 순으로 이루어 졌습니다 대회 진행방식은 자율주행 학습을 위한 대회용 계정이 각 팀에 주어지게 되는데욥 일정 기간동안 주어진 트랙을 얼만큼 빨리 완주하는지를 기준으로 순위를 매기게 됩니답
# 차량 학습 방법
예선은 10시간, 본선과 결선은 30시간의 학습용 계정이 주어지게 되는데요 솔직히 이 시간만으로 시행착오 없이 최적의 모델을 만들기란 거의 불가능에 가깝습니다... 물론 보상함수와 파라미터를 매우매우 야무지게 짜서 학습을 진행한다면 몰라도 조건을 바꿔가며 여러번의 시도를 통해 최적의 주행을 찾아야 하기 때문이죠,,,, 간단한 트랙이라도 1시간 정도는 학습을 한다고 가정한다면 10시간 계정으로는 10번의 시도밖에 할 수 없게 되는셈입니다,,,,
그렇다면 주어진 학습용 계정 외에 다른 계정을 통해 여러 시도를 해봐야 하는데요 모델 학습시 aws사의 컴퓨팅 자원을 활용하게 되므로 학습비용을 지불해야 합니다....
하지만 각 계정당 10시간학습 , 5개 모델 생성 까지는 무료로 주어지게 되는데요 이를 활용하여 여러 개의 계정을 만들어 여러번 시도를 통해 최적의 학습방법을 찾으면 됩니다!!
구글 쥐메일에서 abcd+1@gamil.com / abcd+2@gamil.com / abcd+3@gamil.com +숫자 계정은 서로 다른 계정으로 취급되는데요 해당 주소들로 계정 생성을 하게되면 모두 동일한 abcd@gamil.com 계정으로 보안코드가 전송됩니다!!
즉, 한 구글 메일로 여러 aws 학습용 계정을 만들 수 있는 셈이죠!
저는 예본선까지 대략 65개 정도의 계정을 만들어서 학습을 수행했었네욥,,,,, (대회 끝나고 계정 지우느라 애먹었습니다,,,,)
모델 학습은 여러가지 하이퍼 파라미터와 액션 스페이스, 보상함수를 통해 이루어지게 됩니다!
PPO, SAC 학습방법 / 배치사이즈 / 에폭수 / 학습률 / 손실함수 등등 여러 조건들을 조절할 수 있습니다
하이퍼 파라미터 종류
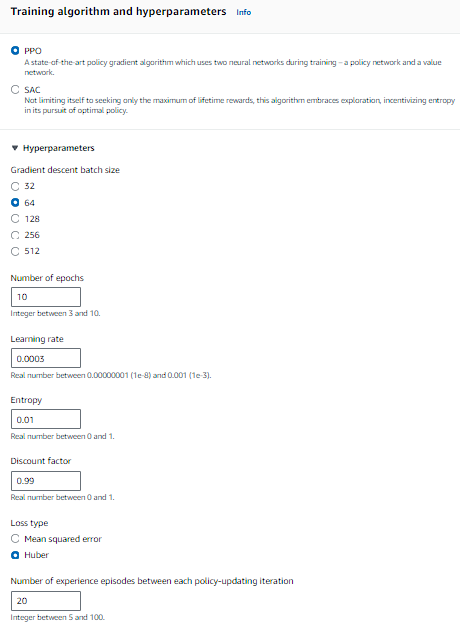
배치사이즈 -> 경사하강법 업데이트에 사용되는 데이터샘플 개수
크면 안정적 추정, 많은 계산리소스 / 작으면 계산 효율성 좋지만 그래디언트 추정 불안정해짐
권장: 64
(크다가 점점 배치사이즈를 줄인 클론모델을 통해 학습 진행시 수렴이 잘됐음)
에폭수 -> 전체 데이터셋 몇번 반복하여 학습할지
크면 오래학습, 과적합위험 / 작으면 학습 불충분
권장: 10
러닝레이트(학습률) -> 가중치 업데이트시 수정강도 결정
크면 발산가능성 존재 / 작으면 학습속도 느려지고 로컬미니마에 갇힐 수 있음
권장: 0.0003(초기 높게) -> 학습 할수록 더 줄이면서 느리지만 안정적 학습 유도하기
엔트로피 -> 에이전트가 많은 탐험수행, 더 좋은길 찾게 유도
크면 더좋은 액션 찾을 확률 높아지지만 훈련시간 늘어남
권장: 0.01(초기 높게) -> 학습할수록 작은값 설정 학습 안정되게
discount factor(할인계수) -> 미래보상 얼마나 고려할지
크면 미래 보상 가치 중요하게 여김
크면 학습 느리지만 주행 안정성 높아짐
작을수록 학습 빨라지지만 모델 안정성 떨어질수 있음
권장: 0.98 ~ 0.995
loss type(손실함수) -> 예측, 실제값 차이 측정
value 모델이 총 보상값(G) 추론시 사용하는 loss 선택
권장: mse(초기) -> huber
num of experience episodes ~
한번 이터레이션에서 모델 업데이트 위한 데이터 수집의 에피소드 수
예) 20 -> 시뮬레이션에서 20번 에피소드 통해 얻어진 데이터로 모델 업데이트
권장: 20 / 학습 불안정, 수렴잘 안될시 더 큰값 설정해보기
액션 스페이스(action space)
액션스페이스는 해당 차량이 어떤 각도와 속도로 주행할 지 지정해주는 것인데욥
Continuous, Discrete 두가지 방법이 존재합니답!
Continuous는 최소, 최대 각도와 속도를 지정해주면 해당 범위 내에서 차랑이 주행하게 됩니다
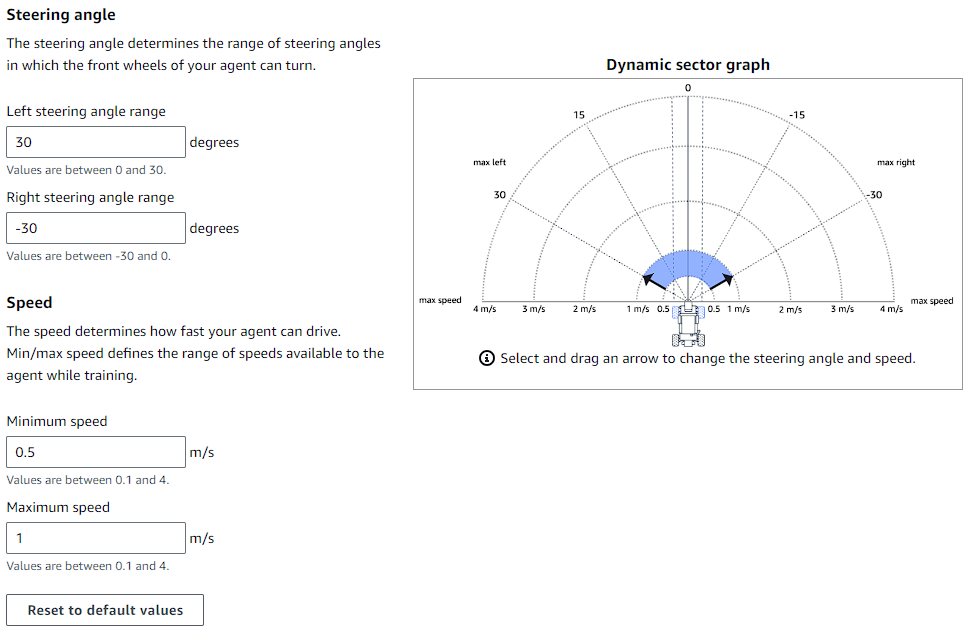
Discrete는 일일이 각도와 해당 각도의 주행속도를 지정해줄 수 있는데욥 총 30개까지 지정할 수 있습니다

보상함수

보상함수는 강화학습의 꽃이라고 할 수 있는데욥 차량이 어떤 행동을 취하면 어느정도의 보상값을 주겠다고 지정해주며 학습을 진행하게 되며 주행트랙의 인덱스 값을 통해 해당 지점에서 오른쪽 왼쪽으로 돌면 보상을 많이 주기 등 다양한 전략과 방법이 존재합니다!!
저는 최적의 주행 경로를 계산한 다음, 해당 좌표에서 해당 최적 경로 방향, 지정한 속도를 사용시 보상값을 크게 주도록 보상하수를 구성하여 학습을 진행하였습니다!!
강화학습이라기보단 정답지가 있는 지도학습, hard coding, 너무 규범적인 방법인 느낌이규 어떤 트랙에서든 먹히는 방법은 아닌거 같도라구요,,,


# 모델 평가 방법
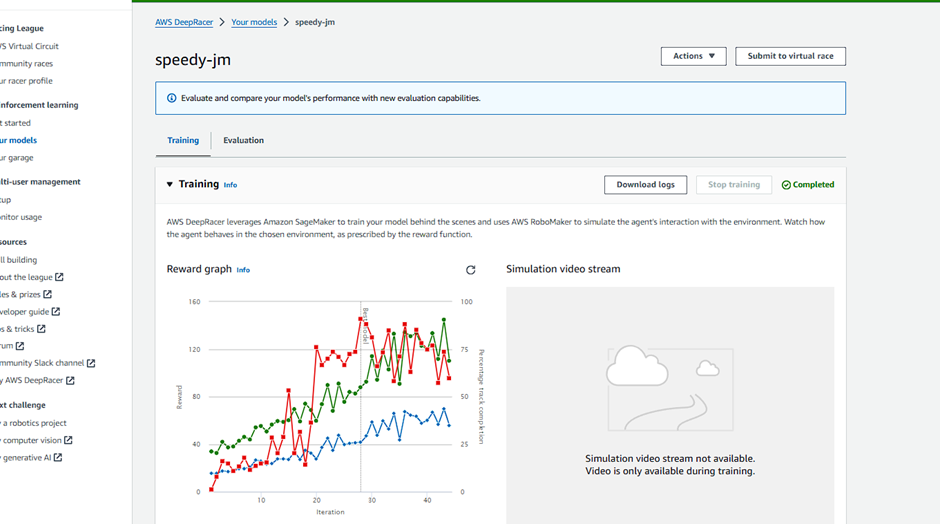
모델이 잘 만들어졌는지 확인하는 방법으로 그래프를 통해 짐작할 수 있습니다
초록색 - 보상값
빨간색 - 평가 완주율
파란색 - 훈련 완주율
훈련 완주율(파란색)이 상승 기미가 보이지 않음 -> 쓸때없는 행동 많이함
세개 그래프 우상향 -> 대체적으로 잘 훈련중이다
우측에서 학습진행중에는 실제 차량이 어떤식으로 주행하는지 동영상으로 확인할 수 있는데욥 이를 확인하는 것도 방법입니다!

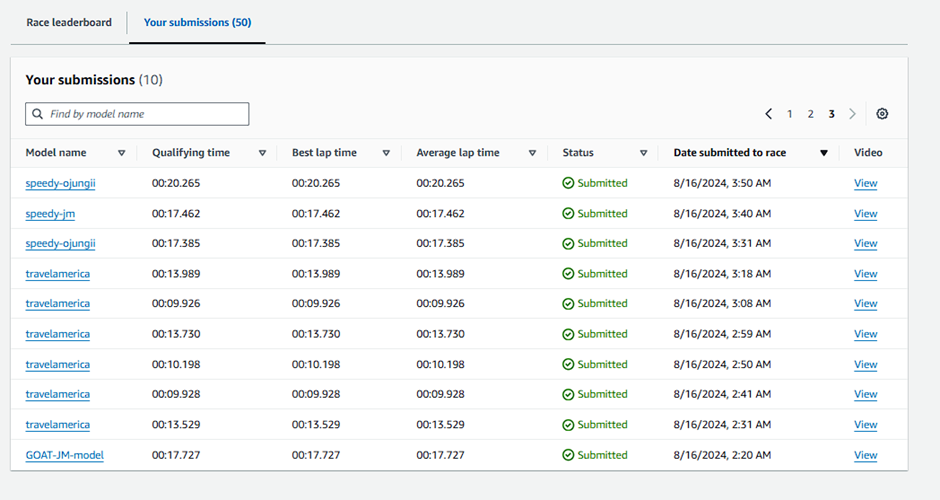
또한, 학습을 완료한 모델은 가상 대회를 열어 여러 번 제출하며 기록값의 분산과 평균을 확인해볼 수도 있습니다
레이스 자동제출 코드
https://github.com/ai-castle/deepracer-lecture-public-data/blob/main/section_11/Automated_Model_Submission_in_CloudShell.md
# 느낀점
저희팀은 예선은 20등으루 턱걸이로 올라간 터라 본선 2주동안 열심히 분비했지만 본선에서는 6등까지 결승 진출인데 결국 8등,,,,,
진짜는 다르다.... 벽이 느껴지도라구요 50번 Submission동안 가장 좋은 기록이 레코드가 되는건뎁 1번 제출로 1등 레코드 달성한 팀두 있었구,,
모든 트랙에서 완벽하게 작동하는 보상함수는 없는 것 같도라구요(있따면 알려주세욥,,,,)
주행 트랙마다 각기 다른 전략을 사용하여 파라미터와 액션 스페이스, 보상함수를 바꿔가며 결과를 확인하는게 베스트인듯 합니답
저희팀은 배치사이즈와 엔트로피를 크게 가져간 후에 완주율이 높으면 파라미터와 보상함수를 수정해가며 여러번 모델 클론을 진행하며 모델을 학습하였는데욥 아쉬움이 많이 남는 대회였습니답
강화학습에 대해 잘 알더라두 대회에 대한 경험치가 중요한 느낌인거 같도라구요
강화학습에 대해 자세히 알 수는 없지만 대략적으로 게임처럼 재밌게(?) 즐겨보구 싶으신 분들에게 추천드립니당,,, 실시간으로 바뀌는 순위 보면 진짜 피말립니당,,,,

# 대회에 참고한 유용한 자료들
https://blog.gofynd.com/how-we-broke-into-the-top-1-of-the-aws-deepracer-virtual-circuit-573ba46c275
How we broke into the top 1% of the AWS DeepRacer Virtual Circuit
Part 2/2 —Ingredients of a high performance model
blog.gofynd.com
https://aravindbhimarasetty.medium.com/rant-against-over-prescriptive-reward-functions-a6bb14b4dab
Rant against over-prescriptive reward functions
I am talking about the reward functions in AWS Deepracer here.
aravindbhimarasetty.medium.com
AWS DeepRacer로 배우는 인공지능과 자율주행 강의 | AI Castle - 인프런
AI Castle | 나만의 AI 자율주행 차를 만들어보세요! AI와 강화학습에 대해 가장 재미있고 빠르게 배울 수 있는 강의입니다. 본 강의는 DeepRacer 대한민국 랭킹 1위 개발자가 제작하였습니다., AWS DeepRac
www.inflearn.com
https://deepracer-school-ko.ai-castle.com/intro.html
AWS DeepRacer School — AWS DeepRacer School (한국어)
aws-deepracer-ko.aicastle.school:443
https://github.com/muhyun/DRL-Workshop/blob/master/Readme-Korean.md
https://github.com/dgnzlz/Capstone_AWS_DeepRacer/blob/master/Compute_Speed_And_Actions/Race-Line-Calculation.ipynb
'Activity' 카테고리의 다른 글
| RAG 넌 누구냐 (3) | 2025.03.04 |
|---|---|
| 데이터분석, AI 연합동아리 지원 후기(투빅스, 보아즈, 비타민) (0) | 2025.01.09 |
| [네이버 부스트캠프] AI Tech 지원 후기 (4) | 2024.07.17 |
| [생성형 AI]stable diffusion - AUTOMATIC1111_ KBS 기술연구소 (1) | 2024.04.30 |
| [생성형 AI]stable diffusion (0) | 2024.04.06 |


