

Hippo's data
Pandas판다스 라이브러리-1 본문
오늘의 포스팅은 판다스Pandas 라이브러리입니다!!

pandas는 python data analysis library 약자인데요
판다스... 판다 아니고 데이터분석을 위한 파이썬 라이브러리 입니다
데이터를 분석하기위해 데이터 구조를 쉽게 변형시키기 때문에 머신러닝이나 딥러닝분야를 공부하면 필수로 알아야하는 라이브러리 입니다
오늘은 책 <모두의 딥러닝-개정3판> 부록을 참고하여 많이 사용하는 판다스 공식들을 알아보겠습니다
목차
A. 데이터 만들기
B. 데이터 정렬하기
C. 행 추출하기
D. 열 추출하기
E. 행과 열 추출하기
F. 중복 데이터 다루기
G. 데이터 파악하기
H. 결측치 다루기
I. 새로운 열 만들기
J. 행과 열의 변환
K. 시리즈 데이터 연결하기
L. 데이터 프레임 연결하기
M. 데이터 병합하기
N. 데이터 가공하기
O. 그룹별로 집계하기
판다스는 기본적으로 두가지 데이터 유형으로 분석을 진행하는데요
1. Pandas Series(1차원)
2. Pandas DataFrame(1차원이상)
먼저 판다스를 알아보기 전에
판다스 데이터 구조인 Series와 DataFrame에 대해 알아보겠습니다
# Series 시리즈 데이터란?
인덱싱된 1차원 배열 -> 인덱스 접근 가능 / 모든 데이터 유형 저장 가능
cf) 엑셀시트 한 열과 유사
행 이름, 열 이름 입력가능
# 시리즈 데이터 예제
리스트형식으로 만들기
0 a
1 b
2 c
dtype: object
딕셔너리 형식으로 만들기
a 2
b 3
c 4
dtype: int64
인덱스값, 밸류값 추출
Index(['a', 'b', 'c'], dtype='object')
array([2, 3, 4], dtype=int64)
*** 명시적 인덱스 -> 해당 인덱스 값으로 접근
*** 묵시적 인덱스 -> 인덱스 위치(번호)로 접근
-> 시리즈 데이터는 명시적, 묵시적 인덱스 둘다 가능함
# DataFrame데이터프레임 데이터란?
-> 시리즈 데이터를 한 열로 취급한 집합
-> 열마다 서로 다른 데이터 타입 가질 수 있음
# Pandas판다스 실습
-> 판다스 설치 (주피터 노트북유형에서 설치시 앞에 ! 붙이기)
A. 데이터 만들기
1. 판다스 라이브러리 불러오기
2. 데이터 프레임 만들기
3. 데이터 프레임 출력
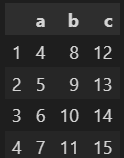
4. 데이터의 열 이름을 따로 지정해서 만들기

5. 인덱스가 두 개인 데이터 프레임 만들기

B. 데이터 정렬하기
6. 특정 열의 값을 기준으로 정렬하기
-> ascending=False 역순정렬 (ascending -> 오름차순)

7. 열 이름 변경하기

8. 인덱스 값 초기화하기
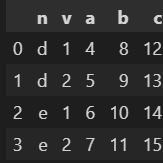
9. 인덱스 순서대로 정렬하기

10. 특정 열 제거하기

C. 행 추출하기
11. 맨 위의 행 출력하기

12. 맨 아래 행 출력하기

13. 특정 열의 값을 통해 추출하기

14. 특정 열에 특정 값이 있을 경우 추출하기

15. 특정 열에 특정 값이 없을 경우 추출하기

16. 특정 열에 특정 숫자가 있는지 확인하기
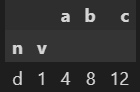
17. 특정 비율로 데이터 샘플링하기

18. 특정 개수 만큼 데이터 샘플링하기
-> 3개 랜덤한 행 추출

19. 특정 열에서 큰 순서대로 불러오기

20. 특정 열에서 작은 순서대로 불러오기
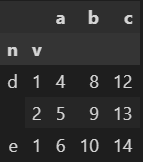
D. 열 추출하기
iloc -> integer location 순서대로 읽기
loc -> 인덱스 라벨값으로 읽기
21.인덱스의 범위로 불러오기

22.첫 인덱스를 지정해 불러오기

23.마지막 인덱스를 지정해 불러오기
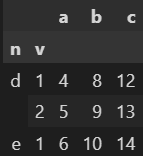
24.모든 인덱스를 불러오기

25.특정 열을 지정하여 가져오기

26.조건을 만족하는 열 가져오기

27.특정 문자가 포함되지 않는 열 가져오기
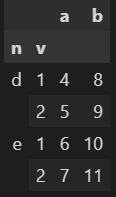
E. 행과 열 추출하기
28.특정한 행과 열을 지정해 가져오기

29. 인덱스로 특정 행과 열 가져오기

30. 특정 열에서 조건을 만족하는 행과 열 가져오기
31. 인덱스를 이용해 특정 조건을 만족하는 값 불러오기
-> 13
F. 중복 데이터 다루기

32. 특정 열에 어떤 값이 몇 개 들어 있는지 알아보기
7 2
4 1
5 1
6 1
Name: a, dtype: int64
33. 데이터 프레임의 행이 몇 개인지 세어보기
-> 5
34. 데이터 프레임의 행이 몇 개인지, 열이 몇 개인지 세어보기
-> (5, 3)
35. 특정 열에 유니크한 값이 몇 개인지 세어보기 # 특정 행 유니크한 값 X
-> 4
36. 데이터 프레임의 형태를 한눈에 보기 / 데이터 요약

37. 중복된 값 제거하기
-> 마지막 행의 중복값들이 사라짐 / 행값이 모두 동일해야 특정 행 지워짐

다음 시간에는 데이터를 파악하는 판다스 문법에 대해 알아보겠습니다.
'Python' 카테고리의 다른 글
| 데이터프레임 다루기2 - 데이터 프레임 변형 groupby, pivot, stack (0) | 2023.12.11 |
|---|---|
| 데이터프레임 다루기1 - 데이터 프레임 조회 및 추출 (1) | 2023.12.10 |
| 데이터분석 관련 함수들-인덱싱,슬라이싱/리스트,튜플,딕셔너리 (2) | 2023.12.10 |
| Pandas판다스 라이브러리-2 (1) | 2023.09.13 |
| Python 모듈, 패키지, 라이브러리 구분 (1) | 2023.08.27 |

