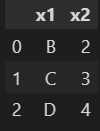
책 <모두의 딥러닝-개정3판> 부록을 참고하여 판다스 Pandas에서 유용하게 쓰이는 공식들을 알아보겠습니다
목차
A. 데이터 만들기 B. 데이터 정렬하기 C. 행 추출하기 D. 열 추출하기 E. 행과 열 추출하기 F. 중복 데이터 다루기 G. 데이터 파악하기 H. 결측치 다루기 I. 새로운 열 만들기 J. 행과 열의 변환 K. 시리즈 데이터 연결하기 L. 데이터 프레임 연결하기 M. 데이터 병합하기 N. 데이터 가공하기 O. 그룹별로 집계하기
loc, iloc -> 행과 관련된
[ ] -> 열 추출
번외) 데이터 프레임 생성시 주의
# 각각 열이름 지정시 -> 열방향으로 입력됨
df = pd.DataFrame(
{"a": [1,2,3],
"b":[4,5,6],
"c":[7,8,9]}
)
df
# columns로 열이름 한번에 지정시 -> 행방향으로 입력됨
df = pd.DataFrame([[1,2,3],
[4,5,6],
[7,8,9]],
columns=['a','b','c'])
df
G. 데이터 파악하기
df
38. 각 열의 합 보기
df.sum()
39. 각 열의 값이 모두 몇 개인지 보기 -> 4개 행임 => 행의 개수와 동일
df.count()
40. 각 열의 중간 값 보기
df.median()
41. 특정 열의 평균 값 보기
df['b'].mean()
-> 9.5
42. 각 열의 25%, 75%에 해당하는 수 보기
df.quantile([0.25,0.75])
43. 각 열의 최솟값 보기
df.min()
44. 각 열의 최댓값 보기
df.max()
45. 각 열의 표준편차 보기
df.std()
46. 데이터 프레임 각 값에 일괄 함수 적용하기 - sqrt 제곱근
importnumpyasnp
df.apply(np.sqrt) # 제곱근 구하기
넘파이 라이브러리 호출 후 계산 (넘파이Numpy -> 벡터 및 행렬연산에 유용)
***apply -> 행or열방향으로 함수 일괄적용
apply(함수 , axis=0 열 / axis=1 행) / 기본값 => axis=0 열
*** apply함수 예제
- 열 방향 sum함수(합) 적용
df.apply(sum, axis=0)
- 행 방향 sum함수(합) 적용
df.apply(sum,axis=1)
H. 결측치 다루기
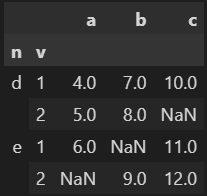
# 넘파이 라이브러리를 이용해 null 값이 들어 있는 데이터 프레임 만들기
df = pd.DataFrame(
{"a" : [4 ,5, 6, np.nan],
"b" : [7, 8, np.nan, 9],
"c" : [10, np.nan, 11, 12]},
index = pd.MultiIndex.from_tuples(
[('d', 1), ('d', 2), ('e', 1), ('e', 2)],
names=['n', 'v']))
df
-> MultiIndex -> 다중인덱스 생성
47. null 값인지 확인하기
pd.isnull(df)
48. null 값이 아닌지를 확인하기
pd.notnull(df)
49. null 값이 있는 행 삭제하기 / null 값 있는 열 삭제 -> df.dropna(axis = 1)
df_notnull = df.dropna()
df_notnull
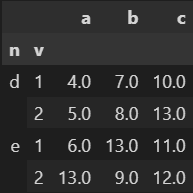
50. null 값을 특정한 값으로 대체하기
df_fillna = df.fillna(13)
df_fillna
-> null값을 13으로 대체
51. null 값을 특정한 계산 결과으로 대체하기
df_fillna_mean = df.fillna(df['a'].mean()) # a열의 평균 값으로 대체
df_fillna_mean
I. 새로운 열 만들기
# 새로운 열 만들기 실습을 위한 데이터 프레임 만들기
df = pd.DataFrame(
{"a" : [4 ,5, 6, 7],
"b" : [8, 9, 10, 11],
"c" : [12, 13, 14, 15]},
index = pd.MultiIndex.from_tuples( # 인덱스를 튜플로 지정합니다.
[('d', 1), ('d', 2), ('e', 1), ('e', 2)],
names=['n', 'v'])) # 인덱스 이름을 지정합니다.
df
52. 조건에 맞는 새 열 만들기
df['sum'] = df['a']+df['b']+df['c']
df
-> sum이라는 새로운 변수(열) 생성
53. assign()을 이용해 조건에 맞는 새 열 만들기
df = df.assign(multiply=lambdadf: df['a']*df['b']*df['c']) # a,b,c열의 값을 모두 곱해 d열을 만들어 줍니다.
df
-> multiply변수 생성 - a,b,c 값 모두 곱한값
54. 숫자형 데이터를 구간으로 나누기 - qcut
df['qcut'] = pd.qcut(df['a'], 2, labels=["600이하","600이상"]) # a열을 2개로 나누어 각각 새롭게 레이블을 만들라는 의미
df
55. 기준 값 이하와 이상을 모두 통일시키기 lower -> 이하값 / upper 이상값 변환
df['clip'] = df['a'].clip(lower=5,upper=6) # a열에서 5이하는 모두 5로, 6 이상은 모두 6으로 변환