
Hippo's data
[TSF] 시계열 데이터 교차 검증(Cross-Validation) 전략 본문
[TSF] 시계열 데이터 교차 검증(Cross-Validation) 전략
Hippo's data 2025. 11. 9. 01:22TSF(시계열 예측) task에서 사용되는 다양한 검증기법 및 시계열에서 K-fold가 사용 가능한 case에 대해 정리해보았담
1. 홀드아웃 (Holdout) - Simple Time Split Validation
-> 데이터를 특정 시점 기준으로 나누어 이전은 학습, 이후는 검증 (1번 split)

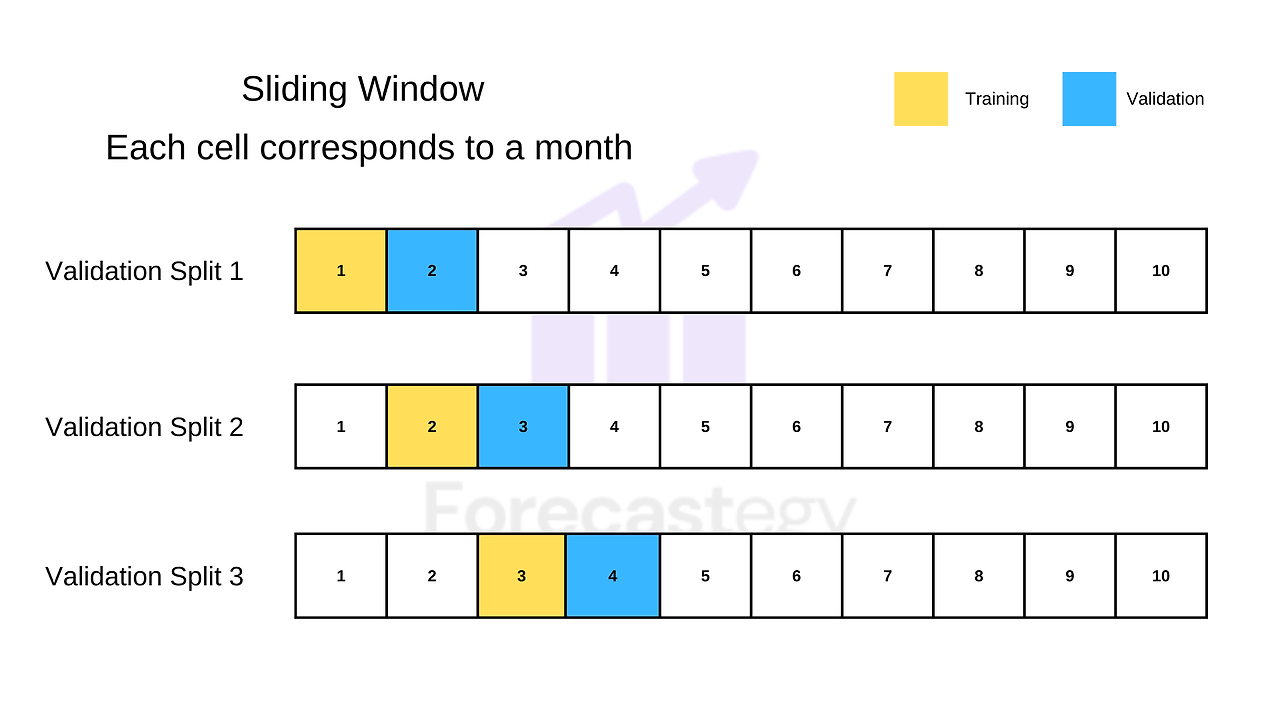
2. Sliding Window Validation (Rolling Window)
-> 고정된 크기의 학습 및 검증 윈도우를 시간 순서대로 이동시키면서 여러 개의 split을 생성
-> 최근 데이터가 중요한 경우
3. Expanding Window Validation (Walk-Forward)
-> 학습 윈도우를 점진적으로 확장하면서 검증 윈도우는 고정 크기로 유지
-> 모든 과거 데이터가 중요한 경우

4. Gap 추가 (1,2,3 방법 모두 적용 가능)
-> 학습 세트의 마지막 시점과 검증 세트의 첫 시점 사이에 간격을 두는 방법, 검증을 더욱 견고하게함
하단의 그림은 2번 Sliding Window Validation에 gap 추가

5. K-fold cv (특정 case에만 가능)

# 시계열 데이터에서 일반적인 K-fold 방식 권장하지 않는 이유
-> 데이터 누수 (Data Leakage) - 미래 데이터로 과거를 예측하는 상황 발생
하지만 시계열 데이터에서도 일반적인 K-fold 검증방식을 사용가능한 경우에 대한 주장존재
# K-fold 방식 적용가능한 case
제목: A note on the validity of cross-validation for evaluating autoregressive time series prediction
저널: Computational Statistics & Data Analysis
https://www.sciencedirect.com/science/article/abs/pii/S0167947317302384?via%3Dihub
https://robjhyndman.com/papers/cv-wp.pdf
https://robjhyndman.com/hyndsight/tscv/
Cross-validation for time series – Rob J Hyndman
robjhyndman.com

-> 과거 시차변수(lag)를 이용하여 모델 학습 후, 잔차의 자기상관성을 검증(Ljung-Box test 등)하여 잔차가 독립적이라면 K-fold 사용가능
잔차(residual)가 독립적 = 모델이 시간 의존성을 완전히 학습 -> 남은 오차는 순수 노이즈(백색잡음)
# 잔차가 독립적일 때, K-fold 사용 가능한 이유?
각 행이 과거 정보를 feature로 포함: lag1, lag2, lag3 등으로 필요한 시간 정보 인코딩
행row 간 시간적 의존성 없음: 모델이 시간 패턴을 완벽히 학습해 잔차는 랜덤 노이즈만 존재
데이터 누수 없음: 무작위로 섞어도 미래 정보가 과거로 흐르지 않음(이미 각 행은 해당 시점보다 과거 정보 lag만 피쳐로 가짐)
주의) 먼 시점을 예측하는 경우, K-fold 검증시에는 실제 과거 lag값을 사용하지만 배포 시점에는 예측된 과거 lag값을 사용하게 되므로 오차가 누적되어 입력될 수 있음
-> K-fold 교차검증이 실제 배포 성능보다 낙관적으로 나올 수 있음
reference
https://vcerq.medium.com/9-techniques-for-cross-validating-time-series-data-7828fc3f781d
9 Techniques for Cross-validating Time Series Data
Exploring the pros and cons of different cross-validation approaches for time series
vcerq.medium.com
https://forecastegy.com/posts/time-series-cross-validation-python/
How To Do Time Series Cross-Validation In Python
One can’t simply use a random train-test split when building a machine learning model for time series Doing it would not only allow the model to learn from data in the future but show you an overoptimistic (and wrong) performance evaluation. In real-life
forecastegy.com
'Time Series Analysis (시계열 분석)' 카테고리의 다른 글
| [TS] 시계열 용어 정리 (0) | 2026.01.31 |
|---|---|
| [TSF] 예측 스텝 전략 (0) | 2025.10.27 |
| [시계열 분석] ARIMA Procedure, SARIMA (0) | 2025.02.13 |
| [시계열 분석] ARIMA Model (2) | 2025.02.12 |
| [시계열 분석] Time Series Regression (0) | 2025.02.10 |



