
Hippo's data
ch2지도학습_회귀regression의 선형모델 linear_model 본문
ch2지도학습_회귀regression의 선형모델 linear_model
Hippo's data 2023. 9. 8. 20:05오늘은 지도학습 중 선형모델(linear model)에 대해 알아보겠습니다
선형모델은 선형함수를 만들어 예측하는데요 회귀와 분류 두 방식 모두 이용가능합니다
그중 회귀 방식의 선형모델 실습을 해보도록 하겠습니다
y = wx + b 에서
y => 예측값 (맞출 타겟값 target)
x => 각 입력특성들 (feature)
w => 기울기 = 각 특성x의 가중치
b => y절편
w,b -> 모델이 학습할 파라미터
-> w[0]: 0.393906 b: -0.031804
-> wave데이터에서 학습한 선형회귀 모델의 파라미터값
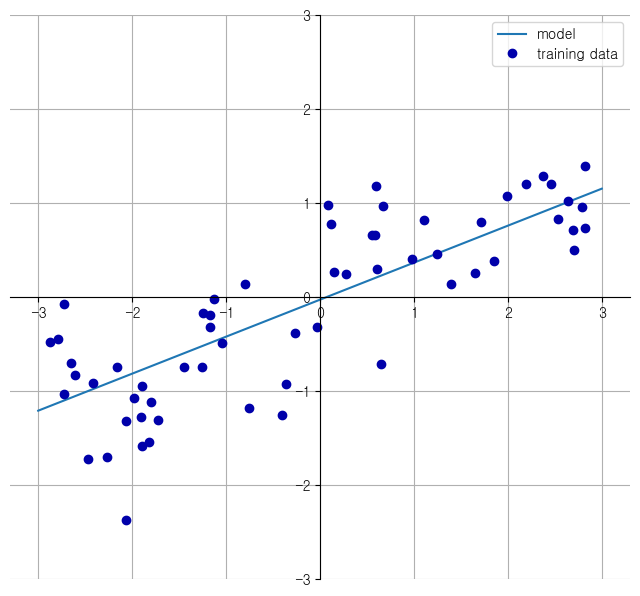
-> 특성1개인 1차원 회귀 모델이므로 2차원 그래프에 표현됨
-> 특성2개 : 2차원 회귀모델(평면)
-> 특성 여러개 : 초평면 hyperplane 회귀모델
*** 변수가 데이터보다 많을시 타겟y 완벽예측 가능
(선형대수 방정식(훈련데이터)보다 미지수(모델 파라미터)가 많은 경우 - 불충분한 시스템 underdetermined system 참고)
# 선형회귀linear regression(최소제곱법 OLS - ordinary least squares)
-> 평균제곱오차(MSE - mean squared error)를 최소화하는 파라미터 w,b 찾기
-> 매개변수 없음(모델 복잡도 제어 불가능)
*** 평균제곱오차(MSE - mean squared error)란?
-> 실제 타겟값과 예측 타겟값의 차이를 제곱하여 더한 후 데이터 개수로 나눠줌

-> wage 데이터(특성1개) 선형회귀모델 객체 생성
-> 파라미터 w,b값 확인
-> lr.coef_: [0.39390555] / lr.intercept_: -0.031804343026759746
-> coef_ -> y절편 b (실수값) / intercept_ -> 특성x의 가중치 w (Numpy배열 -> 각 x에 대응)
*** coef_, intercept_ -> 매개변수에 밑줄_사용이유??
-> scikit-learn 의 훈련데이터에서 유도된 속성은 항상 끝에 밑줄_ 붙임(사용자지정 매개변수와 구분 위함)
-> 훈련 세트 점수: 0.67 / 테스트 세트 점수: 0.66 (score => R^2값)
-> 과소적합
-> 보스턴 주택가격 데이터(특성여러개) 선형회귀모델 객체 생성
-> 훈련 세트 점수: 0.95 / 테스트 세트 점수: 0.61
-> 과대적합(훈련데이터를 과하게 학습하여 테스트 데이터 점수가 낮음)
# 릿지회귀 Ridge
-> 모델복잡도 제어가능 -> 규제regularization를 이용하여 과대적합 방지할 수 있음
L2 norm 이용 (제곱)
-> 가중치값을 작게(0에 가깝게) 만들기 = w모든 원소가 0에 가깝게(기울기를 작게 만들기)
-> 모든 특성이 출력에 주는 영향을 최소한으로 만들기
-> 훈련 세트 점수: 0.89 / 테스트 세트 점수: 0.75
-> 릿지 회귀 구현 linear_model.Ridge
-> 알파값 alpha 조정 -> 키울수록 계수 0에 가까워짐(규제 많이검) -> 훈련세트 성능bad/일반화관점good (알파클수록 모델 복잡도 감소)
-> alpha = 0.00001 -> 선형회귀 훈련 테스트 점수와 완전 동일해짐 / 알파 작으면 계수를 거의 제한하지 않음
-> alpha = 10 -> 훈련 세트 점수: 0.79 / 테스트 세트 점수: 0.64

<규제regularization 효과 이해>
-> 알파값에 따라 모델 coef속성(w가중치값) 변화 조사 -> 알파 매개변수가 모델을 어떻게 변형시키는지 이해
-> 높은알파값 -> 제약 많이줌 -> 작은알파값보다 coef절댓값 크기 작을것임 -> 모델 복잡도 감소
-> alpha =10 -> 계수값 -3~3사이 위치 -> 알파=1,0.1 -> 알파값 작아질수록 계수 크기 범위 커짐
-> Ridge클래스 매개변수 solver -> 여러 알고리즘 적용 가능
-> solver : auto(기본값), svd, cholesky, lsqr, sparse_cg, sag, saga
-> 각각이 의미하는 바는 추후 알아보도록 하자

-> 알파값 고정 alpha =1 / 훈련데이터 크기 바꿔가며 결정계수R^2값 변화 비교
*** 학습곡선 learning curve -> 데이터 크기 따른 모델 성능변화 관찰
-> 릿지에 규제적용되므로 선형회귀보다 훈련셋 점수 낮지만 테스트 셋 점수는 더 높음
-> 두 모델 모두 데이터 많아질수록 성능 좋아짐 / 마지막에 선형회귀가 릿지 점수 따라잡음
-> 데이터 충분하면 규제항 덜 중요해지므로 선형, 릿지 성능 유사해짐
# 라쏘회귀 Lasso
L1 norm 이용 (절댓값)
-> 릿지와 기본 목적은 동일 = 모든 특성이 출력에 주는 영향을 최소한으로 만들기 (가중치 값을 0에 가깝게)
-> 절댓값을 이용하므로 특정 계수는 0이됨 -> 특성선택 feature selection 효과
-> 훈련 세트 점수: 0.29 / 테스트 세트 점수: 0.21 / 사용한 특성의 개수: 4
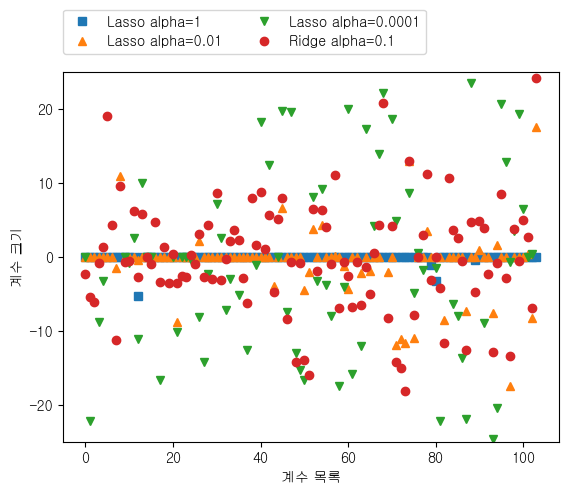
-> 알파값 작을수록 모델 복잡도 증가(규제 약해지므로) -> 많은 특성을 사용함 -> 모델 성능 좋아짐(과대적합 주의)
-> 알파=0.1 릿지 / 알파0.01 라쏘 -> 성능비슷 / 릿지는 계수값 0이 되지 않음(제곱규제이므로)
-> 보통 라쏘보다 릿지를 선호함 / 특성 많고 일부 특성만 중요할시 라쏘 이용, 분석쉬운 모델 원할시 라쏘이용(특성 0으로 만들어 일부만 사용하므로)
->엘라스틱넷 elastic net -> 릿지 + 라쏘 결합 ->L1, L2규제 위한 매개변수 2개 조정해야함
다음 시간에는 분류용 선형모델에 대해 알아보겠습니다!
'ML(Machine Learning) > 책: 파이썬 라이브러리를 활용한 머신러닝(2판)' 카테고리의 다른 글
| ch2지도학습_나이브베이즈 분류기 Naive bayes classifier (0) | 2023.09.10 |
|---|---|
| ch2지도학습_분류classification의 선형모델 linear_model (0) | 2023.09.10 |
| ch2지도학습_K-최근접이웃 K-Neareset Neighbors(K-NN) (2) | 2023.09.07 |
| ch1 붓꽃(iris) 품종분류예제 (2) | 2023.09.05 |


