

Hippo's data
[Paper review] VIT(Vision Transformer) 본문
Paper: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (Alexey Dosovitskiy et al.)
- Conference: ICLR 2021
- GitHub Repository: https://github.com/google-research/vision_transformer
- ArXiv: https://arxiv.org/abs/2010.11929
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
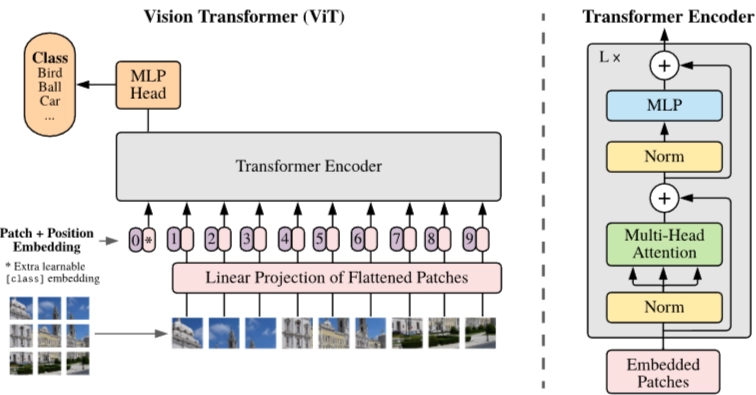
→ 이미지를 패치단위로 분할하여 Transformer 적용
1. SUMMARIZE
| 항목 | 핵심 내용 |
| Problem | NLP는 Transformer가 표준이나, 비전은 여전히 CNN이 주류 • 기존 비전 모델은 이미지의 지역성(Locality)과 이동 불변성(Translation Invariance)이라는 Inductive Bias에 지나치게 의존 |
| Method | VIT(Vision Transformer) 1. Transformer Encoder input • Image 패치화 (Patch) • Flatten + Linear Projection • CLS 토큰 추가, Position Embedding 2. Transformer Encoder • MSA(Multi Head Self-Attention), MLP • Layer Normalization (LN) • Residual Connections 3. MLP Head |
| Results | 대규모 데이터셋에서 SOTA 달성 • ImageNet(중간 규모)에서는 Inductive Bias 부족으로 성능이 낮으나, JFT-300M(초대규모) 사전 학습 시 데이터 양으로 이를 극복하며 최신 CNN 모델을 압도. • 동일 성능 대비 CNN보다 계산 비용(Computational Cost)이 더 효율적 |
| Contribution | • 이미지를 픽셀 그리드가 아닌 패치 시퀀스로 정의하여, 비전 문제를 NLP 방식으로 해결하는 프레임워크 제시 • 복잡한 CNN 없이 "대량의 데이터 + 기본 Transformer" 조합 |
2. DETAIL
1. Introduction
NLP 분야 → Transformer 도입 성공
CV분야 → 여전히 CNN 아키텍처 지배적, CNN + Self Attention 연구 진행
→ Transformer 구조 CV분야에 직접 적용하는 방식 제안
2. RELATED WORK
CV 분야 Transformer 도입 접근방식
- 이미지에 Self-Attention 직접 적용 → 각 모든 픽셀에 대해 어텐션 → $O(N^2)$
- 다양한 근사(approximate) 방식 시도(국소적, 희소(sparse), 축별(axial) 어텐션)
- VIT와 가장 유사한 선행연구
- Paper: On the Relationship between Self-Attention and Convolutional Layers (2020, Cordonnier et al.)
- 2 X 2 패치 → Self-Attention (CNN 국소적인 정보처리능력을 작은 패치단위 어텐션을 통해 대체)
- 고정된 패치단위 연구 → 작은 해상도만 처리 가능 (2x2 패치)
- VIT
- 더 큰 크기 패치→ 더 큰 해상도 처리가능, 큰 데이터셋 학습 가능
3. METHOD
3.1 VISION TRANSFORMER (VIT)
$$
\begin{aligned}
\mathbf{z}_0 &= [\mathbf{x}_{\text{class}}; \mathbf{x}_p^1 \mathbf{E}; \cdots ; \mathbf{x}_p^N \mathbf{E}] + \mathbf{E}_{\text{pos}}, && \mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}, \mathbf{E}_{\text{pos}} \in \mathbb{R}^{(N+1) \times D} & \text{(1)} \\
\mathbf{z}'_\ell &= \text{MSA}(\text{LN}(\mathbf{z}_{\ell-1})) + \mathbf{z}_{\ell-1}, && \ell = 1 \dots L & \text{(2)} \\
\mathbf{z}_\ell &= \text{MLP}(\text{LN}(\mathbf{z}'_\ell)) + \mathbf{z}'_\ell, && \ell = 1 \dots L & \text{(3)} \\
\mathbf{y} &= \text{LN}(\mathbf{z}_L^0) && & \text{(4)}
\end{aligned}
$$
📌VIT 과정
|
1. Transformer Encoder input
$$
\begin{aligned}
\mathbf{z}_0 &= [\mathbf{x}_{\text{class}}; \mathbf{x}_p^1 \mathbf{E}; \cdots ; \mathbf{x}_p^N \mathbf{E}] + \mathbf{E}_{\text{pos}}, && \mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}, \mathbf{E}_{\text{pos}} \in \mathbb{R}^{(N+1) \times D} & \text{(1)}
\end{aligned}
$$
- 이미지 패치
- 원본이미지($x∈R^{H×W×C}$) → P X P 개의 패치로 분할($x_p∈R^{N×(P^2⋅C)}$)
- H: 높이 / W: 너비 / C: 채널 (RGB = 3채널)
- 패치 총 개수 N = H×W / $P^2$
- 평탄화(Flatten)
- 1D 시퀀스
- 선형투영(Linear Projection)
- $E∈R^{(P^2⋅C)×D}$ → D차원 임베딩 벡터로 변환
- CLS 토큰 추가
- 패치 임베딩 제일 앞
- 최종 이미지 분류에 사용됨
- $\mathbf{x}_{\text{class}}$
- 위치 임베딩(Position Embedding)
- 각 패치들의 공간적 위치 정보를 유지하기 위함
- $E_{pos}∈R^{(N+1)×D}$
2. Transformer Encoder
- Multi-Head Self-Attention (MSA)
- $\begin{aligned}
\mathbf{z}'_{\ell} &= \text{MSA}(\text{LN}(\mathbf{z}_{\ell-1})) + \mathbf{z}_{\ell-1}, & \ell &= 1 \dots L & \text{(2)}
\end{aligned}$
- $\begin{aligned}
- MLP
- $\begin{aligned}\mathbf{z}_\ell &= \text{MLP}(\text{LN}(\mathbf{z}'_\ell)) + \mathbf{z}'_\ell, && \ell = 1 \dots L & \text{(3)}\end{aligned}$
- Layer Normalization (Norm)
- MSA, MLP 전 적용(Pre-LN)
- Residual Connections (+)
- MSA, MLP 이후 적용
- input값을 해당 출력에 직접 더해주는 방식
- 모델이 깊어질때, 학습이 안정되도록
- = skip connection
- $\begin{aligned}
\mathbf{z}'_{\ell} &= \text{MSA}(\text{LN}(\mathbf{z}_{\ell-1})) + \mathbf{z}_{\ell-1}, & \ell &= 1 \dots L & \text{(2)}
\end{aligned}$ - $\begin{aligned}\mathbf{z}_\ell &= \text{MLP}(\text{LN}(\mathbf{z}'_\ell)) + \mathbf{z}'_\ell, && \ell = 1 \dots L & \text{(3)}\end{aligned}$
3. MLP Head
- MLP input: $\begin{aligned}\mathbf{y} &= \text{LN}(\mathbf{z}_L^0) && & \text{(4)} \end{aligned}$
- $z^0_L$ : Transformer Encoder 마지막(L번째) CLS(0번째 인덱스) 토큰
- Transformer Encoder 의 결과 y를 최종 MLP Head 입력
- Pre-train: “one hidden layer” → 선형 계층 + 활성화 함수(GELU) + 선형 계층
- $W_2(σ(W_1y+b_1))+b_2$
- Fine-tuning: “single linear layer” → 선형계층
- $W_1y + b_1$
- Pre-train: “one hidden layer” → 선형 계층 + 활성화 함수(GELU) + 선형 계층
Inductive bias
| 📌Inductive bias → 모델이 가지고 있는 기본 가정 예) CNN → Locality → 이미지는 가까운 픽셀간 강한 연관성이 있다 RNN → Sequentiality, Temporal Dependence → 현재 정보는 과거의 정보에 영향을 받는다 |
→ CNN에 비해 VIT Inductive bias 약함
- CNN
- 지역성(Locality) → filter를 통한 Convolution 연산은 특정 픽셀 주위만 고려
- 2차원 구조 보존 → filter는 2차원 이미지를 슬라이딩하며 공간적 구조 보존
- VIT
- MLP(Transformer 인코더 내부) → 각 토큰별로 비선형 연산 → 지역성(Locality)
- Self-Attention →각 패치는 다른 모든 패치에 대해 어텐션 연산 적용 → 전역적(global)
→ 오히려 VIT의 낮은 Inductive bias → 대규모 데이터셋에 강점
Hybrid Architecture
→ 원본 이미지 패치가 아닌 CNN이 추출한 feature map(Convolution 연산)을 Transformer 입력으로 사용
- CNN의 Inductive bias(지역성) + VIT의 Inductive bias(전역성) 결합
- 적은 데이터 셋에서는 VIT보다 좋은 성능, 데이터가 많아질 때, VIT와 성능차이 줄어듦
3.2 FINE-TUNING AND HIGHER RESOLUTION
→ 대규모 데이터 셋에서 pre-train된 VIT모델 → downstream tasks 맞춰 Fine-tuning
- Fine-tuning 방법 (classification task)
- 기존 prediction head(MLP Head) 교체 (D × K feedforward layer)
- D: 모델 hidden dimension
- K: downstream task에서 Class 수
- prediction head 가중치 0 초기화(zero-initialize)
- 기존 prediction head(MLP Head) 교체 (D × K feedforward layer)
- pre-train보다 높은 해상도의 이미지로 Fine-tuning → 성능 향상에 도움됨
- (낮은→ 높은) 해상도: 패치 크기는 일정, 패치 개수 증가
4. EXPERIMENTS
4.1 SETUP
- Dataset:
- Pre-train: ILSVRC-2012 ImageNet, ImageNet-21k, JFT-300M(1만 8천개 클래스, 1천4백만 이미지)
- Transfer learning: ImageNet, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102, VTAB (Visual Task Adaptation Benchmark) - (Natural, Specialized, Structured 세 종류 총 19task)
- Model Variants:
- VIT(Base, Large, Huge)
- ResNet(BIT): Baseline - CNN, Group Normalization(기존 Batch Normalization)
- Hybrid: CNN Featuremap → input
- Training & Fine-tuning:
- Pre-Train, Fine-tuning
- Metrics:
- Fine-tuning Accuracy
- Few-Shot Accuracy
4.2 COMPARISON TO STATE OF THE ART

→ 가장 큰 VIT 모델 ViT-H/14가 여러 Task에서 좋은 성능달성
→ BIT, Noisy Student보다 적은 계산 자원
→ 동일한 VIT 모델에서도, 사전학습 데이터셋이 클 수록, 더 좋은 성능
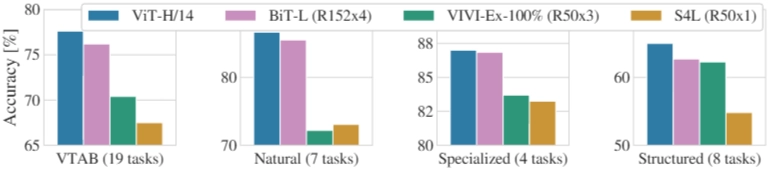
→ VTAB task 정확도
→ 가장 큰 VIT 모델 ViT-H/14가 여러 Task에서 좋은 성능달성
4.3 PRE-TRAINING DATA REQUIREMENTS
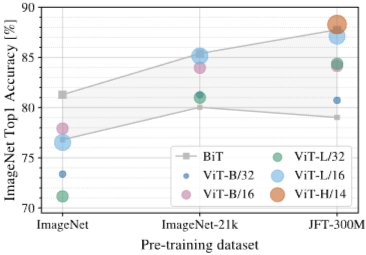
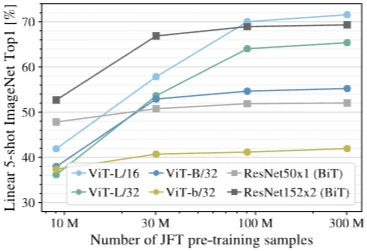
→ 데이터셋 규모에 따른 ViT 모델 성능
- ViT → 대규모 데이터셋으로 사전 학습 → 최고 성능(CNN 능가)
- CNN Inductive bias(지역성) → 작은 데이터셋에서 이점 / 큰 데이터셋에서는 VIT의 유연성이 강점
4.4 SCALING STUDY
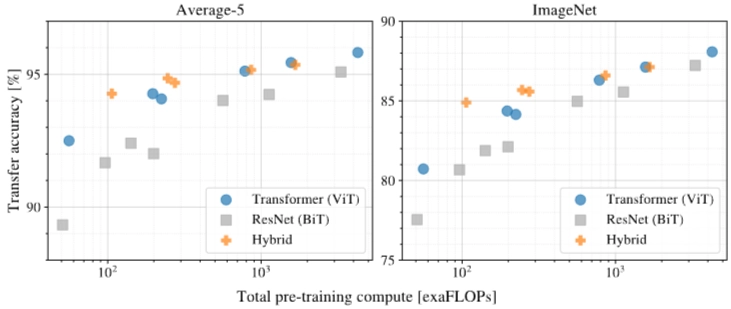
→ 모델별 계산비용, 전이학습 성능 비교
- VIT - 파란색원이 ResNet(BIT) - 회색사각형보다 전반적으로 높은 성능
- 동일한 계산비용으로 ResNet(BIT) 보다 VIT가 더 높은 성능을 보임 (계산 효율성)
- 낮은 계산비용→ VIT보다 Hybrid가 높은 성능 / 높은 계산비용 → VIT가 높은 성능
- 낮은 계산비용 단계에 CNN의 inductive bias 여전히 유용
4.5 INSPECTING VISION TRANSFORMER
→ ViT 모델이 이미지 데이터를 내부적으로 어떻게 처리하는지 (동작방식 이해)

→ CLS 토큰이 입력 이미지의 어떤 패치(patch)들에 가장 강하게 어텐션(attention)했는지
| 📌Attention Rollout → 모델이 입력데이터 어디를 보고 판단했는지 (XAI) → 트랜스포머 여러 레이어를 거치면서 정보 섞임 (2번째 어텐션 맵은, 1번째 레이어의 출력값에 대한 어텐션 스코어/ 최종 CLS 토큰에는 모든 레이어 어텐션 결과 누적됨) 계산방법: → Multi-Head Self-Attention 가중치 헤드 평균 → 각 레이어 걸쳐 재귀적으로 곱함 |
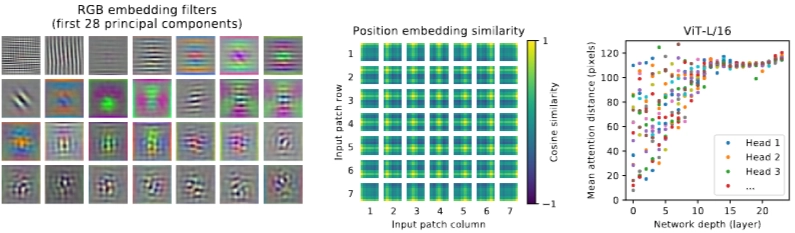
(좌)
$\begin{aligned}
\mathbf{z}_0 &= [\mathbf{x}_{\text{class}}; \mathbf{x}_p^1 \mathbf{E}; \cdots ; \mathbf{x}_p^N \mathbf{E}] + \mathbf{E}_{pos}, & \mathbf{E} &\in \mathbb{R}^{(P^2 \cdot C) \times D}, \mathbf{E}_{pos} \in \mathbb{R}^{(N+1) \times D} & \text{(1)}
\end{aligned}$
E 행렬 → PCA → 시각화
- E 행렬: 이미지 패치 평탄화(Flatten) → 선형투영(linear projection) → Transformer 입력차원에 맞춘 가중치
- 특정한 패턴 보임 → 이미지의 저차원 표현 학습
(중앙)
→ 패치 1D 위치 임베딩간 코사인 유사도
- 각각 자기 위치에 해당하는 부분의 유사도가 가장 큼, 패치 거리가 멀수록 유사도 작아짐
- = 이미지 내의 거리 개념을 효과적으로 인코딩 = 1D 위치 임베딩이 패치들의 이미지 내 공간정보(2D)를 효과적으로 포착
(우)
→ 레이어 깊이에 따른 평균 어텐션 거리
- 초반 - 다양한 어텐션 거리 → 깊이가 증가할수록, 대부분 헤드 평균 어텐션 거리 증가
- CNN vs VIT
- CNN → inductive bias → 지역적인 정보 반영
- VIT → 초기부터 다양한 관점에서 학습
4.6 SELF-SUPERVISION
→ 자기지도학습 효과 실험
BERT의 마스크드 언어 모델링 참고 → 이미지 패치 50% 마스크 처리 → 해당 패치 평균 색상 예측
결과:
- 분류 다운스트림 태스크 파인튜닝 전, *가중치 *사전 학습(pre-training) → 지도학습, 자기지도학습
- 성능 순) 무작위 가중치 < 자기지도학습 < 지도학습
- 자기지도 학습이 어느정도 효과있음,
- 지도학습보다 효과 약함
3. Implementation
https://github.com/NoCodeProgram/deepLearning/blob/main/transformer/vitTransfer.ipynb
deepLearning/transformer/vitTransfer.ipynb at main · NoCodeProgram/deepLearning
Contribute to NoCodeProgram/deepLearning development by creating an account on GitHub.
github.com
- 데이터셋: CIFAR-10 (32x32 크기의 10개 클래스 이미지: 비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭) (train:5만장 / test: 1만장)
- 목표: 10 종류 이미지 classification
- 모델: VIT
- 파라미터
| 📌 optimizer: AdamW learning rate: 1e-3 loss: CrossEntropyLoss batch size: 128 epoch: 100 📌 img_size = 32 # 입력 이미지 크기 (CIFAR-10: 32x32) patch_size = 4 # 패치 크기 (4x4) in_channels = 3 # 입력 채널 (RGB) embed_dim = 48 # 패치 임베딩 차원 num_heads = 4 # 멀티헤드 어텐션 헤드 수 dropout = 0.1 # 드롭아웃 비율 num_layers = 4 # Transformer 인코더 레이어 수 num_classes = 10 # 분류 클래스 수 (CIFAR-10) mlp_ratio = 4.0 # FFN(FeedForward) 중간 레이어 차원 비율 |
- 결과: Test Accuracy: 70.31% (100 에폭)

- 예시 이미지 8개 각 분류 결과(확률)
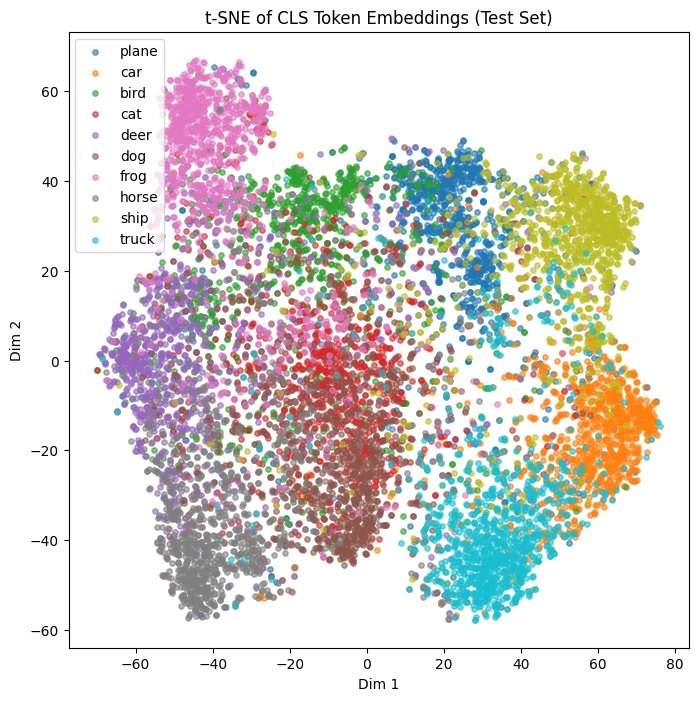
- 10000개 예제 이미지 모델 마지막 레이어 CLS 토큰 임베딩 분포
- t-SNE로 2차원(embed_dim = 48차원 → 2차원)으로 분류결과 시각화
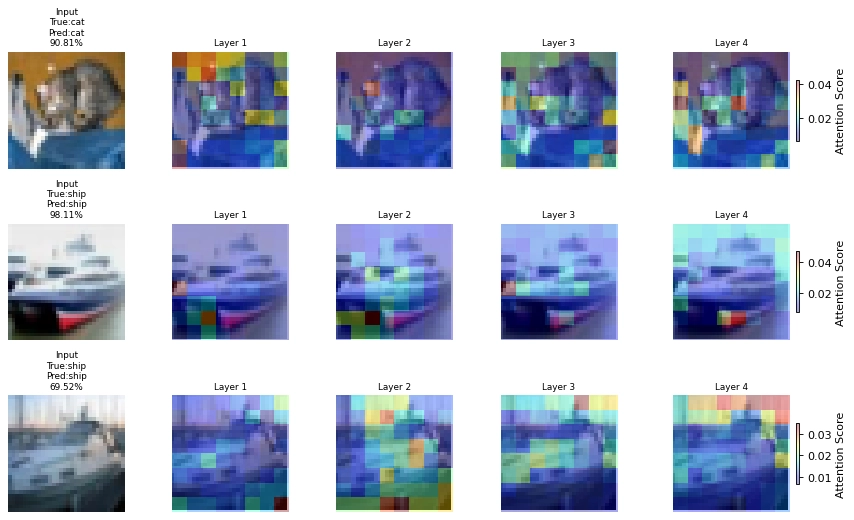
- Vision Transformer(ViT) 모델의 각 레이어별 CLS 어텐션 맵 시각화
- 각 레이어(4)가 입력 이미지의 어떤 부분(패치)에 집중하는지 확인
- 레이어별 특징 추출 차이 시각화
4. Discussion
중요!!!! Swin Transformer ← locality! (baseline)
- ViT + CNN Inductive Bias(지역성)
- TSF - PatchTST
- PatchTST 논문명: A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS
- VIT 에서 패치 단위 분할 방식 착안
- VIT 논문명: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are serve
arxiv.org
'Paper review' 카테고리의 다른 글
| [Paper review] TimeXer (0) | 2026.03.03 |
|---|---|
| [Paper review] TimesNet (0) | 2026.02.10 |
| [Paper review] Pre-LN(Pre-Layer Normalization) (0) | 2026.02.09 |
| [Paper review] iTransformer (1) | 2026.02.04 |
| [Paper review] PatchTST (0) | 2026.01.30 |



