
Hippo's data
[Paper review] TimeXer 본문
TimeXer
Paper: TIMEXER: EMPOWERING TRANSFORMERS FOR TIME SERIES FORECASTING WITH EXOGENOUS VARIABLES
(Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, Mingsheng Long)
- Conference: NeurIPS 2024
- GitHub Repository: https://github.com/thuml/TimeXer
- ArXiv: https://arxiv.org/abs/2402.19072
GitHub - thuml/TimeXer: Official implementation for "TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous
Official implementation for "TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables" (NeurIPS 2024) - thuml/TimeXer
github.com
TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables
Deep models have demonstrated remarkable performance in time series forecasting. However, due to the partially-observed nature of real-world applications, solely focusing on the target of interest, so-called endogenous variables, is usually insufficient to
arxiv.org
TimeXer = Time Series Transformer with eXogenous variables
→ 트랜스포머 구조를 이용하여 내생 + 외생변수를 효과적으로 활용하여 예측하는 모델
1. SUMMARIZE
| 항목 | 핵심 내용 |
| Problem | 기존 접근 • Channel Independence (CI): 변수 간 상관관계를 무시하여 외부 변수의 도움을 못 받음 - PatchTS, DLinear • Channel Dependence (CD): 내생(Target) 변수와 외생(External) 변수를 구분 없이 단순 결합(Concatenation) 임베딩 - iTransformer, Crossformer, Autoformer / Informer → 현실의 시계열 예측에는 내생변수 + 외부요인(외생변수) 영향 큰 문제 |
| Method | 1. Endogenous, Exogenous 변수 임베딩 • Endogenous (내생 변수): Patch-wise (패치단위) → 각 시계열 시간적 종속성(Temporal Dependency) 포착, 전역 토큰( Global Token, 내생변수 전체 시계열 요약, 내생-외생 bridge 역할) 생성 • Exogenous (외생 변수): Variate-wise (변수단위) → 전체 시계열을 하나의 토큰으로 압축 2. Attention Mechanism • Self-Attention: 내생변수 - 패치, 전역토큰 → 각 패치 간의 시간적 종속성, 패치와 전체 시계열(전역 토큰) 간의 관계 학습 • Cross-Attention: 외생-내생(전역토큰) 변수 간 관계 학습 |
| Results | short/long-term forecasting 성능 증명, 다양한 현실 시나리오(결측값, 시간/빈도/길이 불일치 등) 적용 가능 |
| Contribution | 복잡한 구조 변경 없이, 표준 Transformer 아키텍처로 내생 변수의 시간적 패턴과 외생 변수의 상관관계를 학습할 수 있도록 하는 범용적인 프레임워크 제안 |
2. DETAIL
1. Introduction
현실 시나리오 → 외생변수 중요
기존 모델의 한계:

- 단변량 예측: 외생 변수 정보 무시 (PatchTST, Autoformer)
- 다변량 예측:
- 모든 변수를 동등하게 취급 → 불필요한 복잡성 (Crossformer)
- 내생/외생 변수 간 관계를 충분히 모델링하지 못함 (iTransformer)
- 실제 외생 변수가 가질 수 있는 불규칙성(결측값, 시간/빈도/길이 불일치 등) 처리하기 어려움 (Transformer 기반 모델 → Point-wise, Patch-wise 토큰)
→ TimeXer 아키텍처 제안

- 내생변수 (Endogenous): x(1)
- 과거 x(1)으로 미래 x(1) 맞춤
- 외생변수 (Exogenous): z(1),z(2),…,z(C)
- 예측의 대상은 아니지만, 예측을 돕기 위해 참조만 하는 외부 요인
→ 다양한 현실 시나리오(결측값, 시간/빈도/길이 불일치 등) 적용 가능
- 각 외생변수를 단일 토큰으로 처리하므로
2. RELATED WORK
2.1 Transformer-based Time Series Forecaster
→ 장기적인 시간 의존성(temporal dependencies), 다변량 상관관계(multivariate correlations) 포착 강점
Transformer 표현의 세분성(granularity)에 따라 분류
- Point-wise (점 단위)
- 각 시점(point)을 하나의 시간 토큰으로 임베딩
- 한계: 국소적인 의미 정보(local semantic information)를 잘 포착하지 못함
- Informer, Autoformer, Pyraformer
- Patch-wise (패치 단위)
- 시계열 데이터를 패치(patch)로 분할, 패치들 간의 의존성을 포착
- PatchTST - 시간 축(cross-time) 어텐션 수행
- Crossformer - 시간 축(cross-time), 변수 축(cross-variate)에서 어텐션 수행
- Variate-wise (변수 단위)
- 전체 시계열의 전역적인 표현 활용 → 다변량 상관관계 포착
- 한계: 변수 간의 관계를 잘 파악, 전체 시계열을 하나의 변수 토큰으로 임베딩 → 내부적인 시간적 변화를 포착하는 능력 부족
- iTransformer - 각 변수를 토큰으로 → 다변량 토큰간 어텐션 → 변수 간 상호 관계 파악

. → former
✧: 다변량 예측 시나리오에 적용될 수 있지만, 명시적(explicit)으로 변수 간의 교차 의존성(cross-variate dependency)을 모델링하지는 않음
- Univariate (단변량): 단일 변수로 단일 변수 예측
- Multivariate (다변량): 여러 변수로 여러 변수 예측
- Exogenous (외생 변수 활용): 예측 대상 변수(내생 변수) 외에 예측에 도움이 되는 외부 정보(외생 변수)를 활용할 수 있는 능력
→ TimeXer는 단변량, 다변량, 외생 변수를 활용하는 시나리오까지 처리 → 범용적인(general) 능력
2.2 Forecasting with Exogenous Variables
외생변수 결합 기존 접근법
- 통계적 기반
- ARIMAX, SARIMAX
- 주로 선형관계 가정, 다수 외생변수 불규칙한 특징 다루는데 한계
- 딥러닝 기반
- TFT - 변수 선택에 중점(해석)
- NBEATSx, TiDE
→ 내생/외생 시계열의 시간 정렬(alignment) 필수
→ 결측값, 불균일한 샘플링 등으로 인해 시간 정렬 어려움
→ TimeXer- 각 외생변수를 변수 토큰(variate token)으로 임베딩 → 문제해결
3. TimeXer

(a) 내생 변수를 패치(patch)로 분할하여 임베딩, 전역 토큰(global token) 도입
(b) 외생 변수를 각 변수 토큰(variate token)으로 임베딩
(c) 내생 변수 각 패치, 전역 토큰 간 Self-Attention
(d) 내생 전역 토큰, 외생 변수 토큰 간 Cross-Attention
Problem Settings
- 입력
- 내생변수(endogenous): $x_{1:T}$ = ${x_1,x_2,…,x_T}∈R^{T×1}$
- 1 ~ T 시점까지 과거값
- 외생변수(exogenous): $z_{1:T_{\text{ex}}}$ = ${z^{(1)}{1:T{\text{ex}}}, z^{(2)}{1:T{\text{ex}}}, \dots, z^{(C)}{1:T{\text{ex}}}} \in \mathbb{R}^{T_{\text{ex}} \times C}$
- C개 외생변수
- 1 ~ Tex 시점까지 과거값
- look-back 길이 유연하게(flexible) 처리 가능
- 외생, 내생변수 길이(look-back) 달라도 처리가능
- $T_{\text{ex}} \neq T$
- 내생변수(endogenous): $x_{1:T}$ = ${x_1,x_2,…,x_T}∈R^{T×1}$
- 출력
- $\hat x = {{x_{T+1}, x_{T+2}, ..., x_{T +S} }}$
- 미래 S 시점의 내생 변수 값 예측
- 모델
- $\hat x_{T+1:T+S}=F_θ(x_{1:T},z_{1:Tex})$
Endogenous Embedding
$$ \begin{aligned} \{ \mathbf{s}_1, \mathbf{s}_2, \dots, \mathbf{s}_N \} &= \text{Patchify}(\mathbf{x}), \\ \mathbf{P}_{\text{en}} &= \text{PatchEmbed}(\mathbf{s}_1, \mathbf{s}_2, \dots, \mathbf{s}_N), \\ \mathbf{G}_{\text{en}} &= \text{Learnable}(\mathbf{x}). \end{aligned} $$
- Patch-wise Token
- 패치화 (Patchify): 내생 변수를 겹치지 않는(non-overlapping) 패치단위로 분할
- 각 패치는 Local Temporal Pattern 표현
- 패치 임베딩 (PatchEmbed): 각 패치 임베딩 $P_{\text{en}}$ (D차원 벡터)
- 패치화 (Patchify): 내생 변수를 겹치지 않는(non-overlapping) 패치단위로 분할
- Global Endogenous Token
- 학습 가능한 전역 토큰 $G_{\text{en}}$ 생성 (VIT, Vision Transformer 에서 영감받음 - learnable global endogenous token)
- 전역 토큰은 거시적 정보(macroscopic) 표현
Exogenous Embedding
$\mathbf{V}_{\text{ex},i} = \text{VariateEmbed}(\mathbf{z}^{(i)}), \quad i \in {1, \dots, C}$
- Variate-level Token
- 각 변수(1~C)가 하나의 토큰으로 임베딩
- 이유
- 결측값, 시간 스탬프, 샘플링 빈도, 길이 불일치 처리
- 각 변수를 패치단위 처리 → 계산 복잡성과 메모리 사용량 큼
- 외생변수의 거시적(Macro) 정보 반영
Endogenous Self-Attention
$$
\begin{aligned}
\text{Patch-to-Patch: } & \mathbf{\hat{P}}^{l,1}_{\text{en}} = \text{LayerNorm} \left( \mathbf{P}^{l}_{\text{en}} + \text{Self-Attention} (\mathbf{P}^{l}_{\text{en}}) \right) \\
\text{Global-to-Patch: } & \mathbf{\hat{P}}^{l,2}_{\text{en}} = \text{LayerNorm} \left( \mathbf{P}^{l}_{\text{en}} + \text{Cross-Attention} (\mathbf{P}^{l}_{\text{en}}, \mathbf{G}^{l}_{\text{en}}) \right) \\
\text{Patch-to-Global: } & \mathbf{\hat{G}}^{l}_{\text{en}} = \text{LayerNorm} \left( \mathbf{G}^{l}_{\text{en}} + \text{Cross-Attention} (\mathbf{G}^{l}_{\text{en}}, \mathbf{P}^{l}_{\text{en}}) \right)
\end{aligned}
$$
- Patch-to-Patch: 패치간 시간 관계 학습
- Global-to-Patch: 전역 토큰(query), 패치 토큰(key, value) → 전역 토큰이 패치 토큰으로부터 시계열 세부 정보 학습
- Patch-to-Global: 패치 토큰(query), 전역 토큰(key, value) → 패치 토큰이 전역 토큰으로부터 시계열 전체 맥락 학습
$\hat{\mathbf{P}}_\text{en}^l, \hat{\mathbf{G}}_\text{en}^l = \left(\text{LayerNorm} \left(\left[\mathbf{P}_\text{en}^l, \mathbf{G}_\text{en}^l\right]\right) + \text{Self-Attention} \left(\left[\mathbf{P}_\text{en}^l, \mathbf{G}_\text{en}^l\right]\right)\right)$
- overall process → 실제 연산은 모든 토큰을 합쳐(concatenation, $\left[\mathbf{P}_\text{en}^l, \mathbf{G}_\text{en}^l\right]$) 3가지 연산이 한번에 수행됨(Self-Attention)
즉, 입력 시퀀스를 [Global_Token, Patch_1, Patch_2, ...] 형태로 Concatenation(연결)한 뒤, Self-Attention
Exogenous-to-Endogenous Cross-Attention
- 전역 토큰은 내생 시계열 정보 요약한 상태 (이전 Self-Attention)
- Cross-Attention → 전역 토큰이 외생변수 정보 학습 (중요한 외생 변수 선택적 가중치)
- 전역 토큰(query), 각 외생 변수 토큰(key, value)
$$
\hat{G}^{n}_{l+1} = \text{LayerNorm}(\hat{G}^{n}_{l+1}) + \text{Cross-Attention}(\hat{G}^{n}_{l+1}, V_{\text{ex}})
$$
Forecasting
- FFN(Feed-Foward network)
- $G_{\text{en}}^{l+1} = \text{Feed-Forward}(\hat{G}_{\text{en}}^{l+1})$
- $P_{\text{en}}^{l+1} = \text{Feed-Forward}(P_{\text{en}}^{n})$
- $\text{FFN}(x) = \text{Activation}(x W_1 + b_1) W_2 + b_2$
- 각 패치, 전역 토큰 FFN 통과
- 비선형성, 복잡한 관계 학습
- Forecasting Loss
- MSE(Mean Squared Error)
- 선형 투영(Linear Projection)
- $Output=Input×W+b$
- $\hat{x} = \text{Projection}([P_{\text{en}}^L, G_{\text{en}}^L])$
- Linear Projection을 통해 최종 예측값 생성
- Encoder-only 구조이므로 한번에 여러시점 예측
- Parallel Multivariate Forecasting
- 각 변수마다 하나는 내생변수, 나머지는 외생변수로 취급 → 병렬적으로 예측 가능
- iTransformer, Crossformer → 모든 변수(C개)를 한 번에 타겟→ 관계학습 → 한번에 모든변수 예측값 뱉어냄
- TimeXer → 각 변수를 타겟(내생)으로 놓고 나머지 외생으로 (C번 수행, 병렬적으로 가능)
- 각 변수 예측시, 가중치 공유(Parameter Sharing) 가능
- 각 변수마다 하나는 내생변수, 나머지는 외생변수로 취급 → 병렬적으로 예측 가능
4. EXPERIMENTS
Setting
- short-term forecasting: Electricity Price Forecasting(EPF) - 5개 전력시장 데이터, 2 외생/1 내생변수
- Look-back: 168 / Prediction length: 24 / Patch length: 24 (non-overlapping)
- long-term forecasting: 7개(ECL, Weather, ETTh1, ETTh2, ETTm1, ETTm2, Traffic)
- Look-back: 96/ Prediction length: 96, 192, 336, 720/ Patch length: 16 (non-overlapping)

Baselines
- Transformer-based: iTransformer, PatchTST, Crossformer, Autoformer
- CNN-based: TimesNet, SCINet
- Linear-based: RLinear, DLinear, TiDE(외생변수 특화)
Metric
- MSE, MAE
4.1 Main Results
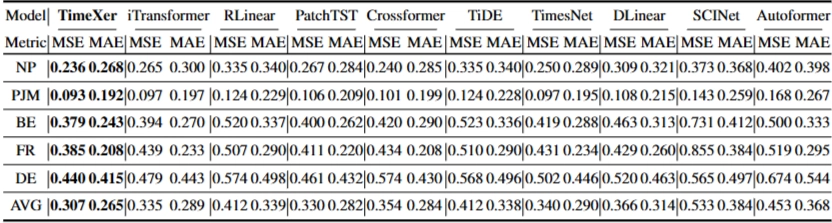
- short-term forecasting
- Transformer based > Linear based (변수간 상호작용 interaction 파악 한계)
- TimeXer SOTA
- Crossformer - 다양한 segment 수준에서 분할 → 불필요한 노이즈(noise) 가능성
- iTransformer - temporal dependency 포착 한계
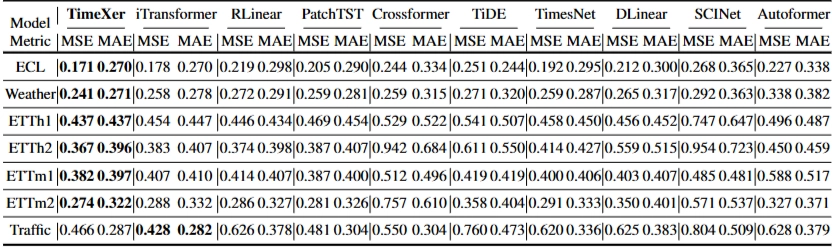
- long-term forecasting
- 대부분 TimeXer SOTA
- MSE > MAE : MSE는 극단적인 오차를 과도하게 반영 (제곱계산)
- 급변 지점 예측
- TimeXer, PatchTST (patch-wise 방식) → 전반적인 추세 잘예측하지만, 급변지점 놓칠 수 있음 (평활화 하는 경향)
- iTransformer (Variate-wise 방식) → 급변지점이 특졍 변수와 강한 연관성 → 구조적 강점traffic dataset → iTransformer 낮은 성능
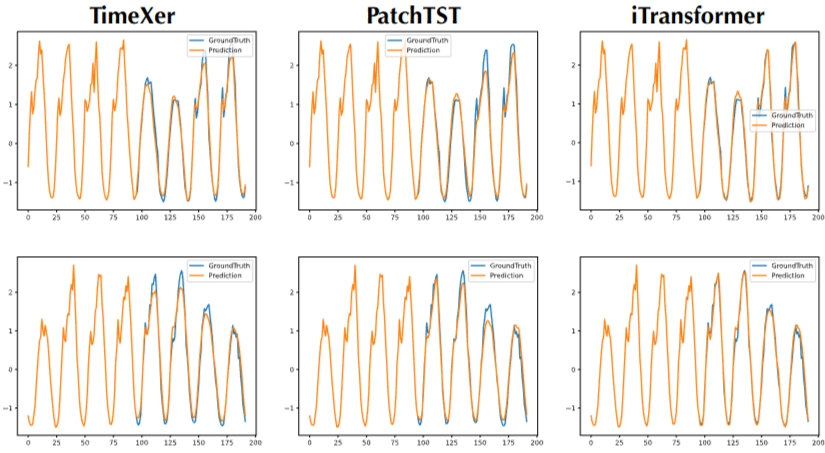
- 대부분 TimeXer SOTA
4.2 Ablation Study
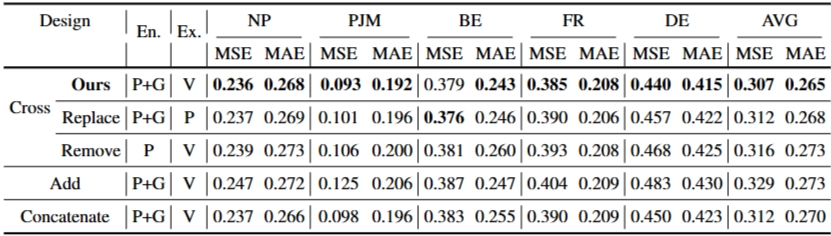
Ex: 외생변수(Exogenous)
En: 내생변수(Endogenous)
P: patch token
G: learnable global token
V: variate token
- Ours(기존 TimeXer): 가장 우수한 성능
- Replace (외생변수 V → P): 외생변수는 세밀한 시간정보를 반영하는 패치 토큰(P) 보다 전체 정보를 담는 변수 토큰(V)이 더 효과적 / 각 변수 패치토큰(P) 임베딩 → 불필요한 노이즈 담길 수 있음
- Remove (내생 G 제거): 전역 토큰(G)이 Bridge 역할 잘 해냄(내생변수 거시적 정보 + 외생변수 정보)
- Add: 기존 Cross Attention → 내생, 외생변수 단순히 더함(Add) - Cross Attention이 외부정보 통합시 유용
- Concatenate: 기존 Cross Attention → 내생, 외생변수 연결(Concatenate) 후, Self-Attention
- Concatenate - 외생변수 간 상호작용 고려 → 단순 Cross Attention 유용
→ 즉, 외생변수는 변수단위 토큰(V) 효과적 / 전역 토큰(G)의 효과 / 변수간 상호작용은 Cross Attention 이 효과적
4.3 TimeXer Generality
4.3.1 Practical Situations
Increasing Look-back Length
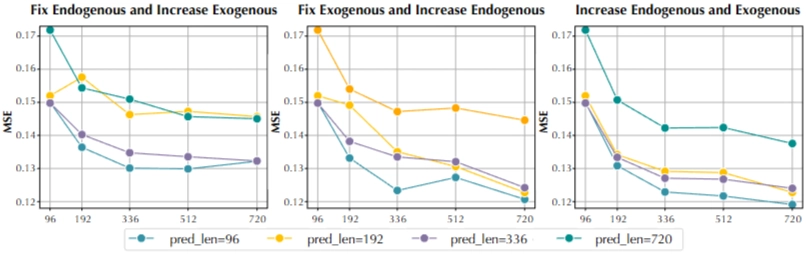
- Look-back Length 길수록, 성능향상
- 특히 외생변수(Exogenous)보다 내생변수(Endogenous) 길이 늘릴 때, 더 큰 성능 향상 (둘다 늘리면 더 좋음)
- 외생변수 길이 성능편차 크지 않음 → 외생 변수간 불일치(misalignment)에도 잘 작동함
Missing Values
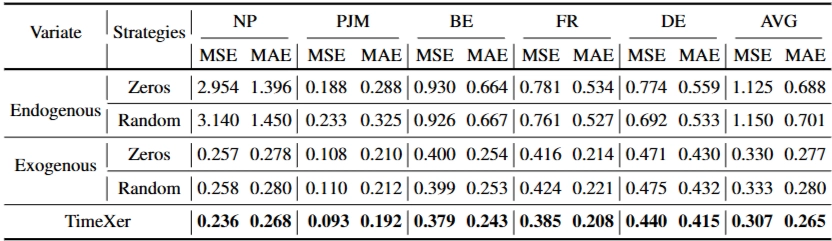
→ 내생, 외생변수 0으로 채움(Zeros) or 랜덤값(0~1범위 무작위)
- 내생변수(Endogenous)에 변화를 줄 시 오차값 큰 변동 → 내생변수(Endogenous)가 예측성능에 직접적 관련
- 외생변수(Exogenous) 변화에는 강건함(Robust) - 성능변동 크지 않음
→ 외생변수가 유용하지 않더라도(결측, 특정값 변형 등), 내생변수가 예측을 주도함
4.3.2 Scalability
→ 큰, 복잡한 데이터셋 얼마나 잘 작동하는지
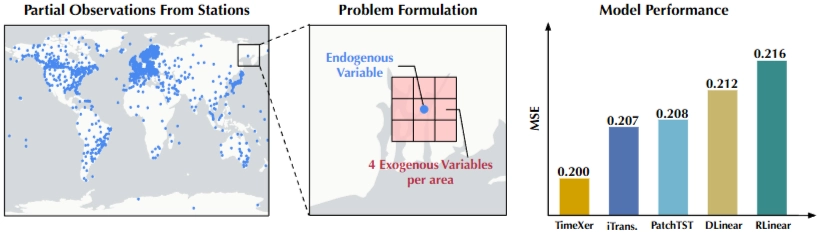
- Dataset : large-scale weather dataset - National Centers for Environmental Information (NCEI)
- 내생변수: 각 관측소 기온 (시간별)
- 외생변수: 각 관측소 근처 기상지표 (내생변수와 샘플링 빈도 다름 - 3시간별)
- TimeXer SOTA
4.4 Model Analysis
Variate-wise Correlations
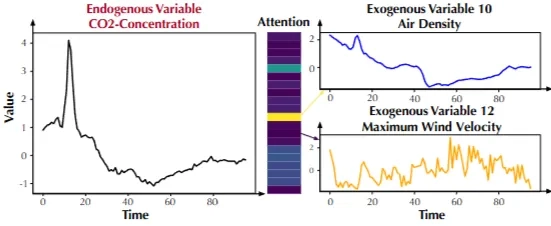
→ 내생변수와 유사한 형태를 보이는 외생시계열이 큰 Attention score를 보임
→ TimeXer의 Cross-Attention이 유용하게 외생 변수를 선택, 해석가능(interpretability) Attention map 제공
Model Efficiency

ECL 데이터셋 - (320개의 외생 변수 - 대규모 시계열 데이터셋)
- 메모리사용, 훈련시간 측면 → TimeXer가 iTransformer보다 효율적
- iTransformer: 모든 변수(외생, 내생)에 대해 Self-Attention
- TimeXer: 외생변수 - variate embedding / 내생 - 외생 변수 상호작용 → Cross-Attention (외생변수간 상호작용 어텐션 생략)
3. Implementation
- Dataset: ETTh1 (중국 전력 변압기 온도 데이터)
- 길이: 2년(2016-2018), 시간단위(17,420 시간)
- Look-back Length: 96 → FCST Length: 24
- 내생변수: Oil Temperature / 외생변수 (6개): HUFL, HULL, MUFL … 등
- 모델 아키텍처
- 입력: [배치, 시계열길이(96), 변수(7)]
- Patch 분할: patch_len=2 → 48개 패치 + Global Token
- 임베딩:
- 타겟(Endogenous): Patch Embedding + PositionalEmbedding
- 외생변수(Exogenous): Variate Embedding (시간→변수)
- 인코더:
- 3개 레이어
- 각 레이어:
- Self-Attention (패치 간 관계)
- Cross-Attention (Global Token ↔ 외생변수)
- FeedForward(Conv1d)
- 헤드:
- Flatten + Linear → 예측값(24시점)
- 파라미터
class Configs:
task_name = 'long_term_forecast'
features = 'MS' # MS: Multivariate-to-Single
seq_len = 96
pred_len = 24
enc_in = 7 # ETTh1: 6개 외생변수 + 1개 타겟
c_out = 1
d_model = 64
d_ff = 128
n_heads = 2
e_layers = 3
patch_len = 4
factor = 3
dropout = 0
activation = 'gelu'
use_norm = True
learning_rate = 0.001
batch_size = 64
epochs = 120

- X/Y축: Patch 토큰들 (P0~P47 → patch length 2로 쪼갠 패치) + Global Token (GLB)
→ 각 인코더 레이어별 패치-글로벌 토큰 Self-Attention 가중치 시각화
→ 레이어별로 서로 다른 구간/패치/글로벌 토큰에 집중하며 다양한 패턴을 학습(레이어 깊어질수록 국소적/세부적 정보에서 거시적/전역적인 정보 포착해나감)

- 각 인코더 레이어별 글로벌-외생변수 어텐션 가중치 시각화
→ 레이어별로 집중하는 외생변수 다름

- 첫번째 레이어 각 헤드별 어텐션 스코어
- Self-Attention (위쪽) - 패치간 Self-Attention
- X축(Key), y축(Query)
- 참조되는 패치→ 시계열을 patch_len=2로 쪼갠 48개 패치
- 각 패치가 어느 패치와 유사한지
- Cross-Attention (아래쪽) - 외생변수, 전역토큰 간 Cross-Attention
- X축(Key): 외생변수 (6개)
- y축(Query): 내생변수 전역토큰 (Global Token)
- Global Token이 예측할 때, 어떤 외생변수를 얼마나 참고하는지
→ 헤드별로 서로 다른 패턴/특징을 학습 중
4. Discussion
- TimeXer는 외생변수를 variate-wise 토큰화함 → 만약 Look-back Window 가 매우 길다면, 토큰화 가정에서 정보손실?, 예측력에 영향? (외생변수의 세밀한 시점 정보가 희석될 수 있음)
- TimeMixer 모델 찾아보기
- 외생변수 또한 Patch 단위로 분할하여 반영한다면?
- Crossformer ->모든 변수를 패치로 쪼개고, 시간과 변수 차원 모두에서 Attention을 수행
- 외생변수도 내생변수처럼 글로번 토큰, 패치화해서 반영한다면?
- 미래 예측시점 실시간 정보 반영하는법? → 외생변수를 늘려서 토큰화 후, input?
'Paper review' 카테고리의 다른 글
| [Paper review] CSDI (0) | 2026.03.09 |
|---|---|
| [Paper review] VIT(Vision Transformer) (0) | 2026.03.03 |
| [Paper review] TimesNet (0) | 2026.02.10 |
| [Paper review] Pre-LN(Pre-Layer Normalization) (0) | 2026.02.09 |
| [Paper review] iTransformer (1) | 2026.02.04 |



