
Hippo's data
[Paper review] CSDI 본문
Paper: CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation (Yusuke Tashiro et al.)
Conference: NeurIPS 2021
GitHub Repository:https://github.com/ermongroup/CSDI
GitHub - ermongroup/CSDI: Codes for "CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation"
Codes for "CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation" - ermongroup/CSDI
github.com
ArXiv: https://arxiv.org/abs/2107.03502
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
The imputation of missing values in time series has many applications in healthcare and finance. While autoregressive models are natural candidates for time series imputation, score-based diffusion models have recently outperformed existing counterparts in
arxiv.org
→ Time-series imputation 에 Diffusion 기법을 도입
1. SUMMARIZE
| 항목 | 핵심 내용 |
| Problem | 기존 시계열 결측치 대체(Imputation) 모델 한계 • 기존 결정론적(Deterministic) 방식은 하나의 값만 예측 → 불확실성(Uncertainty) 측정할 수 없음 • VAE, GAN 기반의 기존 확률론적(Probabilistic) 모델 → 시간적(Temporal) 의존성과 변수(Feature) 간의 상관관계를 동시에 포착하는 데 어려움 |
| Method | CSDI (Conditional Score-based Diffusion Imputation) 1. 조건부 확산 모델 (Conditional Diffusion Model) • 결측치 대체를 조건부 생성 문제로 정의. • 관측된 데이터(Observed values)를 조건(Condition)으로 삼아, 노이즈가 낀 결측치(Missing values)를 역확산(Reverse process) 과정을 통해 점진적으로 복원 2. Transformer 기반 2D Attention • Temporal Attention: 시간 축(Time steps) → 시점간 의존성 모델링 • Feature Attention: 다변량 데이터의 여러 변수(Features) 간 상관관계 모델링 3. 학습 및 추론 (Training & Inference) • 관측된 데이터 중 일부를 인위적으로 마스킹(Masking)하여 타겟으로 삼고, 이를 복원하는 방식으로 자기 지도 학습(Self-supervised learning) 수행 |
| Results | 다양한 시계열 벤치마크에서 SOTA 달성 • 시계열 예측(Forecasting), 보간(Interpolation) 우수한 성능 |
| Contribution | • 시계열 결측치 대체(Imputation) 문제에 스코어 기반 확산 모델(Diffusion Model)을 최초로 적용 • 시간과 변수 축을 모두 고려 -2D Attention 아키텍처를 제안 • 다수의 샘플링 → 결측치에 대한 신뢰 구간(Confidence Interval) → 확률론적 방법론 |
2. DETAIL
1. Introduction
CSDI 제안 → Score-based Diffusion Models을 conditional 방식으로 확장 → 관측값(condition)으로 부터 누락된 값 추정
→ 기존 모델 대비 좋은 성능 달성
2. RELATED WORK
딥러닝 기반 imputation
- 통계적 방법보다 더 정확
- 초기 RNN계열(RNN, LSTM, GRU)
- RNN계열 + GAN, self-training, Attention 메커니즘 기법들 결합
- 결정론적(Deterministic, 특정 값 추정) 뿐만 아니라 확률적(Probabilistic, 분포 추정) Imputation 방식 개발
💡 score-based generative model
노이즈 예측 = Score 계산 Score-Based Generative Modeling through Stochastic Differential Equations https://arxiv.org/abs/2011.13456 |
Score-Based Generative Modeling through Stochastic Differential Equations
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corre
arxiv.org
Diffusion model 도입
- 해당 시기 Diffusion modeld은 비조건부 모델 (imputation은 특정 조건하에 결측치 추정)
- TimeGrad → Diffusion model을 시계열 예측에 도입
- RNN 구조 사용으로 impution에는 부적합(과거→미래 시간의존성)
3. Background
3.1 Multivariate time series imputation
→ 다변량 시계열 imputation 수식적 세팅
$X = {x_{1:K,1:L}} ∈ R^{K×L}$
- X: 시계열 데이터
- K: 피쳐 수
- L: 시계열 길이(length)
$M = {m_{1:K,1:L}} ∈ {{0, 1}}^{K×L}$
- M: 관측된 마스크(observation mask)
- $m_{k,l}=0$ : 누락
- $m_{k,l}=1$ : 관측
$s = {s_{1:L}} \in \mathbb{R}^L$
- s: 시점(time stamp)
Imputation 정의
- 보간(interpolation - 중간 시점 누락 채우기), 예측(forecasting - 미래 시점 누락 채우기) 포함하는 포괄적인 개념
3.2 Denoising diffusion probabilistic models
DDPM(Denoising diffusion probabilistic models)
https://arxiv.org/abs/2006.11239
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound
arxiv.org
- Forward process: 원본 데이터에서 가우시안 노이즈를 추가해나감

- Reverse process: 노이즈 데이터에서 노이즈 제거해나가며(denoising) 원본 데이터로 복구

- Loss function: 실제 추가된 노이즈( $\mathbf{\epsilon}$)를 모델이 정확하게 예측하도록 훈련

→ CSDI: DDPM 프레임워크 기반 + 조건부(Conditional, 조건 = 관측된 데이터) 설정 도입
3.3 Imputation with diffusion models
→ CSDI → 관측값($x_0^{co}$) 을 조건으로 사용하여 누락된 값 ($x_0^{ta}$) 추정
- 기존 Diffusion model → 비조건(unconditional) 방식으로 작동

- $x_{0:T}^{ta}$: imputation target 시퀀스 (0~T)
- $x_0^{co}$: 관측값(conditional observations)
4. Conditional score-based diffusion model for imputation (CSDI)
4.1 Imputation with CSDI
기존 Diffusion 모델에서 관측된 데이터를 조건으로 사용 → 분포를 모델링
4.2 Training of CSDI
Loss function


→ CSDI self-supervised training 도식화
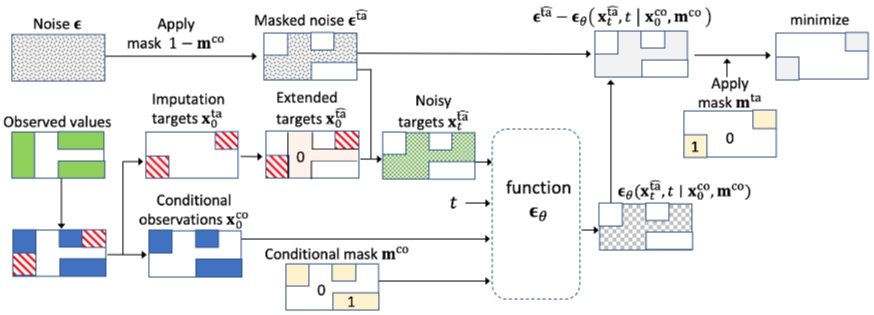
→ 실제 적용시, Zero padding, conditional 추가
- 초기 데이터: 관찰값, 결측/마스킹 값 구분
- 녹색 → 관찰값(Observed)
- 흰색 → 결측 or 마스킹 값
- 관찰된 데이터에서 예측할 타겟, 조건값 분리
- 관찰값(녹색) → 빨간사선(Imputation targets, $x^{ta}_0$), 파란색(Conditional observations, $x^{co}_0$) 분리
- 예측할 타겟값 부분의 실제 노이즈 추가
- 해당 위치의 노이즈값이 들어감
- 빨간사선(Imputation targets, $x^{ta}_0$) 부분 + 회색 점(ϵ, t 시점에 추가된 실제 노이즈) → 녹색 격자(노이즈 섞인 타겟값)
- 타겟값 예측 (t시점, 관찰된 값 이용)
- 녹색 격자(노이즈 섞인 타겟값) + t (확산 forward 단계 시점) + 파란색(Conditional observations, $x^{co}0$) → function $\epsilon_\theta$ → 회색격자 $ϵ_θ(x{t^a},t∣x_0^{co}$) (예측한 노이즈 값)
- 예측값, 실제 노이즈값 비교
- Loss function : $minimize ||\epsilon - \epsilon_\theta(x^a_t, t | x^{co}_0)||$ (실제 노이즈값, 예측 노이즈 값 최소화)
- 회색 점(t 시점에 추가된 실제 노이즈) vs 회색격자 $ϵθ(x{t^a},t∣x_0^{co}$) (예측한 노이즈 값)

→ Conditional observations 으로 Imputation targets을 예측 (=결측(값을 채우는 task)
샘플링(추론), 학습 단계에서 데이터를 어떻게 사용할지
샘플링(imputation, = 추론단계): 누락된 값 채우기
- Imputation targets: 모든 결측치 대상
- Conditional observations: 모든 관측값 대상
학습(training): 누락된 값을 잘 채우도록 모델을 학습
- Imputation targets: 관측된 값 중 부분집합(subset) → 다양한 전략 존재(랜덤, 패턴 등)
- Conditional observations: 관측된 값중 Imputation target(subset)으로 선택되고 남은 값
4.3 Choice of imputation targets in self-supervised learning
| 결측 유형 | 결측 발생 원인 | 예시 | 일반적인 처리 방법 |
| MCAR (완전 무작위 결측, Missing Completely At Random) |
우연 (단순 오류 등) | 통신 오류 → 서버 데이터 삭제 | 결측치가 포함된 행 삭제(Drop), 평균/중앙값 단순 대체 |
| MAR (무작위 결측, Missing At Random) |
다른 데이터(변수) | 주말 → 주식 거래량 누락 | 관측된 다른 변수들을 활용한 대체 및 보간 (interpolation) |
| MNAR (비무작위 결측, Missing Not At Random) |
누락된 값 자체 | 주가 비정상적 폭락 → 주식 호가창 화면 누락 | 도메인 지식 반영, 결측 여부 자체를 새로운 변수(Feature)로 추가 |
→ self-supervised learning imputation 타겟($x^{ta}_0$) 선택 전략 (4가지)
(1) Random strategy
- 사용 시점: test set 결측값 패턴 모를 때
- 방법: [0%, 100%] 범위에서 무작위로 샘플링
- 예: train set 30% 타겟, 나머지 70% 조건 데이터
- 일반화 능력 (다양한 누락 비율에 적응)
(2) Historical strategy
- 사용 시점: 구조화된(structured) 결측 패턴 존재
- 방법:
- 현재 훈련 샘플($x_0$), 다른 무작위 샘플$(\tilde{x}_0)$ 선택
- 현재 훈련 샘플($x_0$)의 관측값, 다른 무작위 샘플$(\tilde{x}_0)$의 결측값의 교집합(intersection)을 imputation 타겟으로
- 현재 훈련 샘플 ($x_0$)에서 타겟으로 선택되지 않은 값은 조건부 관측값($x^{co}_0$)으로
- → train set의 구조화된(structured) 결측 패턴을 학습하는 방식*
- 구조적인 누락 패턴(예: 주말 동시 누락, 특정 센서들의 연쇄 고장 등)' 자체를 모델이 학습, 과적합 가능성 존재
(3) Mix strategy
- 사용 시점: 복합적인 상황(무작위, 구조화된 패턴)
- 방법: 두전략 섞음 (Random + Historical) (논문에서는 1:1비율)
- 두 전략의 장점(일반화 + 결측패턴 학습) 결합
- 과적합(overfitting) 방지, 견고함(robust)
(4) Test pattern strategy
- 사용 시점: test set 결측값 패턴 알 때
- 예) 미래시점 항상 결측치라는 패턴 앎 → forecasting
- 방법: test set 패턴대로 imputation target 설정
5. Implementation of CSDI for time series imputation
간소화 ver

디테일한 ver

- 입력 데이터→ 레이어를 통해 원본 X (K,L) → (K,L,C) 변환 = 피쳐수, 길이, 채널
- 채널 C → 잔차 채널(residual channel) 개수, 하이퍼파라미터
- → $x_0^{Ta}$(imputation target), $x_0^{co}$ (conditional observations) 분리(split)
- 제로 패딩(zero padding): 비어있는 부분을 0으로 채움 → 길이 맞춰줌(K x L)
- 원본 데이터: $X∈R^{K×L}$ (피처 K, 길이 L)
- 관측 마스크 $M$, 조건부 마스크 $m_{co}$
- 관측 마스크 $M$
- 원본 전체 데이터셋 결측값, 관측값 여부 구분 목적
- 1 → 관측값 / 0 → 결측값
- 원본 전체 데이터셋 결측값, 관측값 여부 구분 목적
- 조건부 마스크 $m_{co}$
- 훈련시 ${x_0^{co}}$(conditional observations) 여부 구분 목적
- $m_{co}∈{{0,1}}^{K×L}$ : 1 → $x_0^{co}$ (conditional observations) / 0 → $x_0^{Ta}$(imputation target)
- ${x_0^{co}}$ = $m_{co}⊙X$
- $x_0^{Ta}$ = $(M - m_{co})⊙X$
- 훈련시 관측값 중에, ${x_0^{co}}$로 선택되지 않은 나머지 값(일부러 결측치를 만듦) → 예측 학습을 하기 위함
- 관측 마스크 $M$
- 훈련 (train, Self-supervised learning)
- 원본 관측 데이터(X) 에서 일부를 ${x_0^{co}}$(conditional observations), $x_0^{Ta}$(imputation target)
- ${x_0^{co}}$로 결측치($x_0^{Ta}$)를 예측하는 것을 훈련
- 추론(interence) = 샘플링(imputation)
- 실제 관측된 모든 값을 ${x_0^{co}}$(conditional observations)로 사용 → 결측치 추론
- 모델 아키텍처($\epsilon_\theta$)
- Diffusion T 스텝 50고정
- DiffWave 모델 기반 → DiffWave의 Residual Block 구조를 2D로 확장
- Paper: DiffWave: A Versatile Diffusion Model for Audio Synthesis
- https://arxiv.org/abs/2009.09761
- DiffWave → 디퓨전 모델을 WaveNet에 적용한 오디오 생성모델
- WaveNet→ Causal Convolution 구조(현재, 과거정보로 피처맵 추출) → 미래 시계열 예측 모델
- https://arxiv.org/abs/2009.09761
DiffWave: A Versatile Diffusion Model for Audio Synthesis
In this work, we propose DiffWave, a versatile diffusion probabilistic model for conditional and unconditional waveform generation. The model is non-autoregressive, and converts the white noise signal into structured waveform through a Markov chain with a
arxiv.org
DiffWave: A Versatile Diffusion Model for Audio Synthesis
In this work, we propose DiffWave, a versatile diffusion probabilistic model for conditional and unconditional waveform generation. The model is non-autoregressive, and converts the white noise signal into structured waveform through a Markov chain with a
arxiv.org
- **2D Attention**
- Temporal Transformer (시간축)
- (1,L,C) x K
- 각 피쳐들의 **시간 의존성 포착**
- Feature Transformer (변수 축)
- (K,1,C) x L
- 각 시점들의 **피처간 의존성 포착 (동일 시점 변수간 상관관계)**- Side Information 활용
- Diffusion 단계(t) 임베딩: 현재 diffusion t시점 정수값→ 128차원 임베딩(사인64, 코사인 64개 수식)
- 현재 확산과정 어느 단계에 있는지 더 풍부한 위치정보 제공
- $tembedding (t)
=( \sin(10^0 \cdot \frac{4}{63} t), \dots , \sin(10^{63} \cdot \frac{4}{63} t), \cos(10^0 \cdot \frac{4}{63} t), \dots , \cos(10^{63} \cdot \frac{4}{63} t))$ - → 서로 다른 주기를 가진 128개 사인/코사인 임베딩 벡터 생성
- 시간 임베딩 (Time Embedding): 시계열의 시간적 위치 정보 ($s_l$l)를 모델에 제공 → 128차원 임베딩
- 각 시점의 고유한 시간 정보 제공
- $sembedding(sl)=(sin(sl/τ^{0/64}),…,sin(sl/τ^{63/64}),cos(sl/τ^{0/64}),…,cos(sl/τ^{63/64}))$
- $\tau = 10000$
- → 서로 다른 주기를 가진 128개 사인/코사인 임베딩 벡터 생성
- 범주형 특징 임베딩 (Categorical Feature Embedding): K개의 특징에 대한 피쳐 정보 → 학습 가능한(learnable) 16차원 임베딩
- 각 변수 고유한 특성 할당 (언어모델처럼 문맥적 분석X)
- Diffusion 단계(t) 임베딩: 현재 diffusion t시점 정수값→ 128차원 임베딩(사인64, 코사인 64개 수식)
6. Experimental results
6.1 Time series imputation
Dataset
- healthcare dataset (중환자실 intensive care unit (ICU))
- 35개 변수(feature), 48시점(hourly)
- 결측치: 원본 80% 결측
- 학습: Random strategy, 관측값 10%, 50%, 90% 결측으로 설정
- air quality PM2.5 measurement
- 베이징에서 측정한 36개 관측소 12개월 측정, 각각 36개 시점
- 결측치: 원본 13% 결측
- 학습: mix(random and historical strategy)
Deterministic Imputation → 누락값 단일 값 추청

→ 100개 샘플 5번 실험 CRPS 스코어의 평균, 표준편차
→ CSDI Imputation 성능 SOTA
💡 CRPS(Continuous Ranked Probability Score)
|

- 빨간 X: 관측값
- 파란원: 관측값 중 누락값
- 실선(녹색, 회색): 모델 예측한 imputation의 중앙값(median) (100개 샘플)
- 음영(녹색, 회색): 모델 예측값의 분위수 범위(5~95%) (100개 샘플)
→ CSDI가 누락값을 더 정확하게 예측
Probabilistic Imputation → 누락값 확률적 추정

→ 100개 샘플 중앙값 MAE → 5번 실험 평균, 표준편차
→ CSDI Imputation 성능 SOTA
6.2 Interpolation of irregularly sampled time series
직전 데이터셋과 동일 → irregularly 시간간격(시간 간격을 가까운 분단위로 반올림 → 불규칙하게 - 샘플 길이 각각 달라짐)

→ CSDI Imputation 좋은 성능
6.3 Time series Forecasting
- 5가지 데이터셋 활용
- Test pattern strategy

→ CSDI Imputation 좋은 성능
7. Conclusion
- 한계점: 샘플링 속도 느림 → DDIM - 상미분 방정식(ODE) 활용하여 계산 효율성 개선
- downstream tasks으로 확장 - Classification 등
- 다양한 modalities적용 (시계열을 넘어)
3. Implementation
https://github.com/ermongroup/CSDI
GitHub - ermongroup/CSDI: Codes for "CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation"
Codes for "CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation" - ermongroup/CSDI
github.com
https://github.com/lmnt-com/diffwave
GitHub - lmnt-com/diffwave: DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. - lmnt-com/diffwave
github.com
- 데이터셋:
- ETTh1 (Electricity Transformer Temperature, 7개 변수: HUFL, HULL, MUFL, MULL, LUFL, LULL, OT)
- 원본: 17420 rows × 8 columns(7변수 + 1 time)
- Z-score 표준화 (변수별 mean/std), 슬라이딩 윈도우(길이 72)로 분할 (50%겹치게 → stride = 36)
- [482, 72, 7] 배치수, 시퀀스 길이, 변수 수
- (17420 - 72) // 36 + 1 = 482
- 첫 시퀀스: 0 ~ 71, 두 번째: 36~107, 마지막: (마지막 시작점) ~ (마지막 시작점+71)
- Train/Test = 80%/20% (Train: 385, Test: 97 시퀀스)
원본 데이터 Trendplot

- 학습
- 모델/optimizer:
- CSDI 모델(DDPM기반)
- AdamW optimizer(lr=2e-4)
- CosineAnnealingLR scheduler(epoch 단위)→학습이 진행됨에 따라 학습률을 코사인 곡선 형태로 점진적으로 감소
- 학습 루프: 각 배치마다 마스킹 후 forward/backward, gradient clipping(기울기 폭팔방지→ 제한), Noise Schedule( Linear (β: 0.0001 → 0.02)
- 마스킹 전략: 매 배치마다 결측률 10~50% 랜덤 변동 (자기지도학습 Random strategy)
- Loss: MSE
- 500 epoch, diffusion step: 50
- 랜덤 결측률(10~50%)로 mask 생성
- forward: 랜덤 t 선택 → 노이즈 추가 → 노이즈 예측 → 결측 위치 MSE loss
- backward + gradient clipping (max_norm=1.0)
- optimizer.step()
- ema.update() — shadow 파라미터 (최근까지의 파라미터 변화의 평균값 저장) 갱신
scheduler.step() — epoch 단위
- for batch in train_loader: (1 에폭 요약)
- 모델/optimizer:

- 추론
- EMA 적용(Exponential Moving Average) → 학습시 모델 파라미터값 저장 → 추론시 과도하게 파라미터가 바뀌지 않도록 평균내어 반영
- 샘플 10개씩 추출 → 분포(신뢰구간), 평균내어 단일값 예측
- 실험
- 7개 변수 평균
| Task | 결측 방식 | 평가 대상 | 평가 지표 |
|---|---|---|---|
| Interpolation | 50% 랜덤 결측 | 결측 위치 복원 | MAE, RMSE, CRPS |
| Forecasting | 후반 50% (t=36~71) 전체 결측 | 미래 구간 예측 | MAE, RMSE, CRPS |
| Block Missing | 랜덤 2개 변수 전체 결측 | 변수 전체 복원 | MAE, RMSE |
| Task | MAE | RMSE | CRPS |
|---|---|---|---|
| Interpolation (50%) | 0.3831 ± 0.0685 | 0.5910 ± 0.1200 | 0.1396 ± 0.0279 |
| Forecasting (50%) | 0.6535 ± 0.1289 | 0.8829 ± 0.1819 | 0.2439 ± 0.0534 |
| Block Missing (2 vars) | 0.5791 ± 0.1985 | 0.7184 ± 0.2346 | N/A |
- 테스트 구간 첫번째 시퀀스 시각화


- 테스트 구간 전체 시퀀스 시각화

4. Discussion
- 논문에서는 기본적인 Diffusion 기법(DDPM) → 최신 Diffusion 기법 도입(LDM, 다양한 샘플러 등)
- TimeLDM: Latent Diffusion Model for Unconditional Time Series Generation
- 조건부 고도화 → RAG 기반 시계열 Diffusion
- Retrieval-Augmented Diffusion Models for Time Series Forecasting (RATD)
- https://arxiv.org/abs/2410.18712
TimeLDM: Latent Diffusion Model for Unconditional Time Series Generation
Time series generation is a crucial research topic in the area of decision-making systems, which can be particularly important in domains like autonomous driving, healthcare, and, notably, robotics. Recent approaches focus on learning in the data space to
arxiv.org
Retrieval-Augmented Diffusion Models for Time Series Forecasting
While time series diffusion models have received considerable focus from many recent works, the performance of existing models remains highly unstable. Factors limiting time series diffusion models include insufficient time series datasets and the absence
arxiv.org
'Paper review' 카테고리의 다른 글
| [Paper review] VIT(Vision Transformer) (0) | 2026.03.03 |
|---|---|
| [Paper review] TimeXer (0) | 2026.03.03 |
| [Paper review] TimesNet (0) | 2026.02.10 |
| [Paper review] Pre-LN(Pre-Layer Normalization) (0) | 2026.02.09 |
| [Paper review] iTransformer (1) | 2026.02.04 |



