
Hippo's data
[Paper review] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models 본문
[Paper review] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Hippo's data 2025. 7. 16. 01:29오늘은 ICLR 2024에서 발표된 시계열 예측 분야에 LLM을 도입한 Time-LLM 논문리뷰를 해보겠습니다!

제목: Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
링크: https://arxiv.org/abs/2310.01728
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time series forecasting holds significant importance in many real-world dynamic systems and has been extensively studied. Unlike natural language process (NLP) and computer vision (CV), where a single large model can tackle multiple tasks, models for time
arxiv.org
저는 최근에 시계열 예측 분야 공모전에 참가하면서 시계열 예측과 관련된 여러 모델들에 대해 관심이 생겼는데욥
요즘 다양한 연구들이 LLM분야로 수렴하는 것 현상도 나타나고 있고, LLM분야가 매우 핫한 분야인데욥
그렇다면 시계열 예측분야에서도 LLM이 사용되지 않을까? 라는 궁금증에 여러 자료들을 찾아보던 중 해당 논문을 발견했습니다!

https://opentimeseries.com/python_packages/llm_for_time_series/
| 패키지명 | 설명 |
| Time-LLM | 기존 LLM을 그대로 두고, 시계열 예측에 맞게 재프로그래밍하는 프레임워크 |
| MOMENT | 카네기멜론대(CMU)에서 개발. 범용 시계열 분석을 위한 오픈소스 파운데이션 모델 |
| TimesFM | 구글에서 개발. 다양한 공개 데이터셋에서 제로샷(Zero-shot) 예측 성능이 SOTA에 근접 |
| Lag-Llama | 단변량(하나의 변수) 시계열의 확률적 예측을 위한 범용 파운데이션 모델 |
| MOIRAI | 세일즈포스에서 개발. 인코더 전용 트랜스포머 기반의 범용 시계열 예측 모델 |
| TimeGPT | 최초의 시계열 예측 파운데이션 모델임을 주장하는 모델 |
| Chronos | 아마존에서 개발. LLM 구조를 활용한 사전학습 시계열 예측 모델 |
아니나 다를까 시계열 분야에서도 LLM 모델이 다양하게 연구되고 있다는 것을 확인할 수 있습니다!
저는 이중에서 시계열 데이터를 이용해서 사전학습된 거대 파운데이션 모델을 만드는 분야가 아닌
기존 LLM 모델은 그대로(Backbone) 사용하되, 시계열 특성에 맞게 입출력을 살짝 변형한 Time-LLM에 대해 리뷰해보도록 하겠습니다
목차
1. INTRODUCTION
2. RELATED WORK
3. METHODOLOGY
4. EXPERIENTS
5. CONCLUSION
6. Example Code
1. INTRODUCTION
기존 시계열 모델의 한계
- 시계열 예측분야 예시: 수요 예측, 재고 최적화, 에너지 부하 예측, 기후 모델링 등
- 기존의 시계열 예측 모델은 특정 작업이나 애플리케이션에 특화되어 있어, 작업별로 별도의 설계가 필요
- 반면, 자연어 처리(NLP)나 컴퓨터 비전(CV) 분야 Foundation Models (단일 모델로 여러 작업을 해결)
LLM의 능력
- GPT-3, GPT-4, LLaMA 등 사전 학습된 LLM은 복잡한 시퀀스의 패턴 인식·추론에 강력
- Few-shot/Zero-shot 학습 능력 보유
-> 이러한 LLM의 능력을 시계열 예측 분야에 도입!
LLM의 시계열 데이터 적용의 한계
- 연속적 시계열 vs. 이산적 토큰: 모달리티(modality) 차이
- LLM 사전학습 과정에는 시계열 패턴·도메인 지식 미포함
2. RELATED WORK
-> TIME-LLM이 시계열 예측 분야에서 어떤 기존 연구들과 관련이 있으며, 어떤 점에서 차별화되는지 크게 세 분야로 구분할 수 있습니다!
각 분야에 대해 구체적으로 살펴보겠습니다
2-1. 태스크별 학습 (Task-specific Learning)
2-2. 동일 모달리티 적응 (In-modality Adaptation)
2-3. 교차 모달리티 적응 (Cross-modality Adaptation)
2-1. 태스크별 학습 (Task-specific Learning)
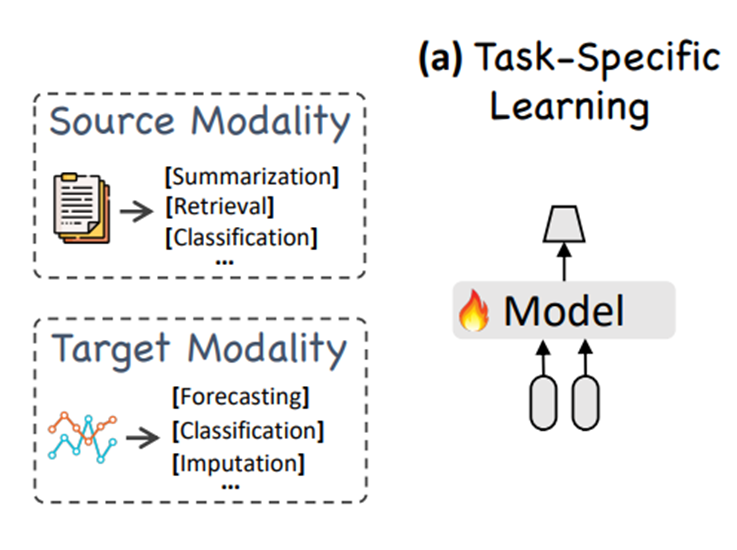
기존 시계열 예측 모델은 특정 도메인, 태스크에 특화
예) 교통 도메인, 에너지 도메인(전력 사용량 예측), 기상 도메인(기온 예측), 금융 도메인(주가 예측)
예) 단변량 시계열 예측을 위한 ARIMA 모델, 시퀀스 모델링을 위한 LSTM, 긴 시간 의존성을 처리하기 위한 TCN 및 트랜스포머 기반 모델
End-to-End 학습
모델의 입력(과거 시계열 데이터)부터 출력(미래 예측값)까지 전체 과정을 하나의 네트워크로 구성하고, 이 네트워크 전체를 한 번에 학습시키는 방식
-> 평소와 다른 패턴에 제대로 대처하지 못함
한계점: 다재다능함(versatility), 일반화 능력(generalizability) 부족
cf) 특정 분야 특화 운동선수(기존 시계열 모델) VS 만능 스포츠맨(LLM Foundation)
2-2. 동일 모달리티 적응 (In-modality Adaptation)

- 사전 학습(Pre-training)된 모델
- 다운스트림 태스크(특정 작업)를 위한 파인튜닝(Fine-tuning)
-> 시계열 사전 학습 모델(TSPTMs,TimeSeries Pretrained Models) 개발에 초점을 맞춘 연구들이 등장
- '지도 학습’
(예: 과거 데이터를 보고 미래를 예측하는 방식으로 학습)
- '자기 지도 학습’
(예: 시계열 데이터의 일부를 가려놓고 가려진 부분을 맞추는 방식으로 학습)
한계점: 사전 학습에 사용할 수 있는 시계열 데이터의 양이나 다양성이 CV, NLP에 비해 희소(sparse)
# 시계열 사전 학습 모델(TSPTMs) VS 대형 LLM 비교
a. 대표적 시계열 사전 학습 모델(TSPTMs,TimeSeries Pretrained Models)
Chronos 시리즈
– 공개 시계열 및 합성(가우시안 프로세스) 데이터를 합쳐 약 10억 개(10^9) 이상의 시계열 샘플로 사전학습
Tiny Time Mixers (TTM)
– Quick 버전(TTM-Q)은 이 중 2.5억 개(2.5 × 10^8)만 사용하여 단축 학습
– Monash·LibCity 등 공개 데이터 리포지토리에서 약 10억 개(10^9) 샘플을 수집하여 학습
| 모델 계열 | 모델명 | 파라미터 수 |
| Chronos-T5 | chronos-t5-tiny | 8 M |
| chronos-t5-mini | 20 M | |
| chronos-t5-small | 46 M | |
| chronos-t5-base | 200 M | |
| chronos-t5-large | 710 M | |
| Chronos-Bolt | chronos-bolt-tiny | 9 M |
| chronos-bolt-mini | 21 M | |
| chronos-bolt-small | 48 M | |
| chronos-bolt-base | 205 M | |
| Tiny Time Mixers (TTM) | TTM-E (Advanced) | 5 M |
| TTM-M (Standard) | 4 M | |
| TTM-Q (Quick) | 1 M |
b. 대표적 대형 LLM
| 모델 | 파라미터 수 |
| GPT-2 (base) | 124 M |
| GPT-2 (XL) | 1.5 B |
| GPT-3 | 175 B |
| LLaMA-2 | 7 B / 13 B / 70 B |
- 대형 범용 LLM과 비교하면 시계열 LLM은 여전히 10–100배 정도 작음
- 대형 LLM과 비교할시, 여전히 상당한 격차가 존재
2-3. 교차 모달리티 적응 (Cross-modality Adaptation)

-> 대표적으로 2가지 방식 존재
a. 다중 모달 파인튜닝 (Multimodal Fine-tuning)
- 여러 종류의 데이터(예: 시계열 데이터와 시계열에 대한 설명 텍스트)를 함께 사용하여 모델을 파인튜닝하는 방식
예) LLM4TS - https://arxiv.org/pdf/2308.08469
- LLM을 사용하여 시계열 예측을 위해 두 단계 파인튜닝 프로세스를 설계
b. 모델 재프로그래밍 (Model Reprogramming)
- 사전 학습된 모델의 핵심 가중치는 고정
- 모델의 입출력 부분만 살짝 변환, 모델 내부를 크게 건드리지 않음
예) Voice2Series - https://arxiv.org/pdf/2106.12987
- 시계열을 음향 모델에 적합한 형식으로 편집
GPT4TS - https://arxiv.org/pdf/2310.01728
- One Fits All(OFA) (Zhou et al., 2023a)
- 사전 학습된 언어 모델의 Self-Attention 및 Feedforward 레이어를 변경하지 않고 활용
- 다양한 시계열 분석 태스크에서 파인튜닝 과정 거침
TIME-LLM의 차별점
-> 세 범주중, 사전학습된 백본(Backbone))모델의 가중치는 고정하고 모델 입출력 부분만 시계열에 맞게 살짝 변형한
2-3. 교차 모달리티 적응 (Cross-modality Adaptation) 범주에 속함
핵심 기법
1. Model Reprogramming
2. Prompt-as-Prefix(PaP)
이제 Tirme-LLM 동작방식에 대해 구체적으로 알아보겠습니다!
3. METHODOLOGY
크게 5가지 동작 방식으로 구분되는데욥 각 부분에 대해 구체적으로 살펴보겠습니다!
3-1. Normalization
3-2. Patching
3-3. Patch Reprogramming
3-4. Prompt-as-Prefix (PaP)
3-5. Pre-trained LLM Body & Output Projection

3-1. Normalization
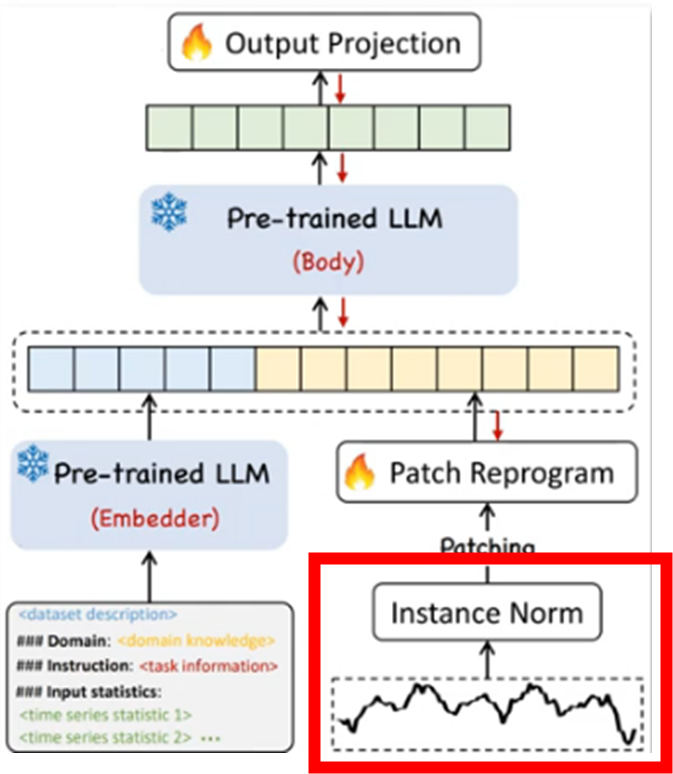
reversible instance normalization (RevIN)
- 각각의 변수를 독립적으로 정규화(개별적으로 평균 0, 표준편차 1 되도록) -> 결과 되돌릴 수 있도록 설계
- 시계열 예측의 결과 복원에 유리 (최종 예측결과 복원 위함)
시계열 데이터의 분포 변화(distribution shift)를 완화
- Distribution shift는 시계열 데이터의 통계적 속성이 시간이 지남에 따라 변화하는 것
3-2. Patching
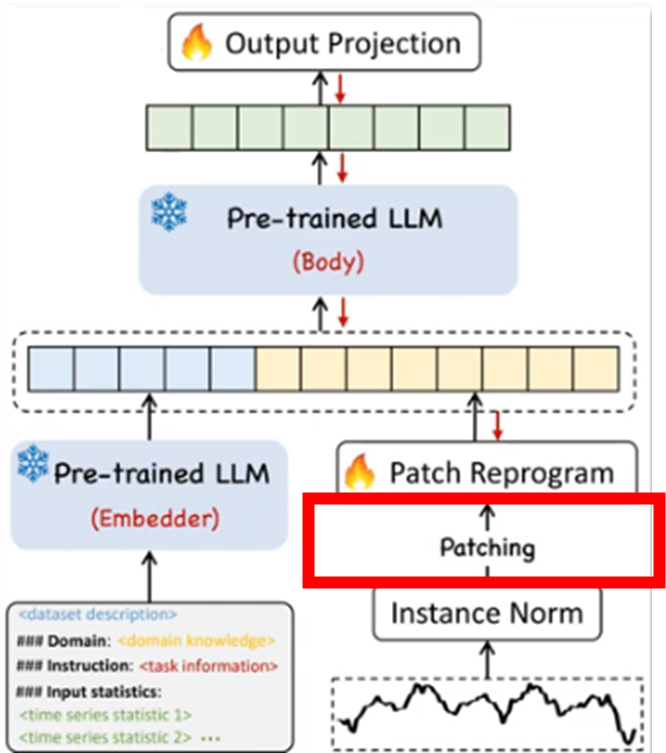

- 입력 시계열 데이터 X^(i) (N개의 1차원 변수 중 i번째 변수)를 여러 개의 짧고 연속적인 덩어리(patch)으로 나눔
- 각 패치의 길이 L_p 인 총 P개의 덩어리(patch) 생성
목적
1. 지역 의미 정보 보존
- 시계열 데이터를 작은 덩어리로 나누면 각 덩어리(패치) 내에 포함된 지역적인 시간 패턴이나 특징을 더 잘 포착하고 보존가능
2. 토큰화 역할
- 자연어 처리에서 문장을 단어(토큰)로 나누는 것처럼, 시계열 데이터를 LLM이 처리할 수 있는 이산적인 토큰 시퀀스 형태로 만듦
3. 계산 부담 감소
- 긴 시계열 전체를 한 번에 처리하는 것보다 패치 단위로 나누어 처리함으로써, LLM 내부 (특히 어텐션 메커니즘)의 계산량과 메모리 사용량 줄임
3-3. Patch Reprogramming
a. 패치 임베딩 (Patch Embeddings)
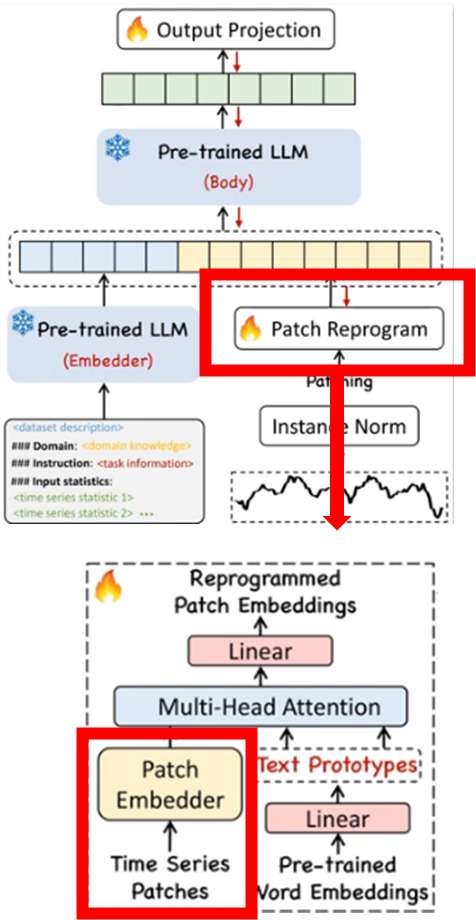

- 패치 형태로 표현된 시계열 데이터를 LLM의 입력으로 적합한 차원(d_m)의 연속적인 벡터 표현으로 변환
- 본 논문에는 선형변환 이용
- 최종적으로 패치 임베딩 (Patch Embeddings) 생성
b. Text Prototypes (텍스트 프로토타입)

- Pre-trained Word Embeddings 공간 - 다양한 언어적 개념들의 벡터가 담겨있음 (백본 LLM word embedding 공간)
- 대표 개념 벡터 학습 - 방대한 언어 공간에서 시계열 예측에 가장 유용한 소수의 대표 벡터(Text Prototypes)들을 정의
- Text Prototypes - ‘상승', '하락', '주기', '계절', '평균', '최고점', '최저점' 등 시계열 데이터의 특징을 설명할 수 있는 수많은 언어적 개념에 해당하는 벡터
- 텍스트 프로토타입이 시계열 예측 오차를 최소화하는 방향으로 학습 과정에서 최적화
- 최종적으로 Text Prototypes 생성
c. 패치 임베딩 + 텍스트 프로토타입(text prototypes, 단어집합)과 결합

멀티 헤드 크로스 어텐션(multi-head cross-attention)
- 패치 임베딩은 쿼리(Query)
- 텍스트 프로토타입 임베딩은 키(Key)와 값(Value) 역할
- 시계열 데이터의 각 패치(Query 역할)가 어떤 텍스트 프로토타입(Key 및 Value 역할)과 관련이 깊은지 학습
어텐션 계산

- 시계열 데이터의 해당 패치가 LLM이 이해하는 '언어적' 의미 공간 내에서 어떤 특징을 가지는지 포착
예) "짧은 상승(short up)" 또는 "꾸준한 하락(steady down)"과 같은 시계열 특성을 설명하는 언어적 단서를 학습
3-4. Prompt-as-Prefix (PaP)

-> 시계열 데이터 및 예측 작업에 대한 추가적인 정보를 담은 자연어 프롬프트 임베딩(Prompt Embeddings)을 입력 시퀀스의 접두사(prefix)로 추가
활용예시)
[Domain]: We usually observe that electricity consumption peaks at noon, with a significant increase in transformer load
[Instruction]: Predict the next 96 steps given the previous 512 steps information attached
[Statistics]: The input has a minimum of 12.5, a maximum of 45.2, and a median of 30.1. The overall trend is upward. The top five lags are 24, 168, 720, 8760, 365.
-> 데이터셋 설명, 작업 지침, 입력 시계열의 통계(평균, 추세, 주요 지연 값 등)와 같은 정보를 통해 LLM이 시계열 데이터의 특성을 더 잘 이해하고 예측을 수행하도록 유도
3-5. Pre-trained LLM Body & Output Projection
Pre-trained LLM Body
- 프롬프트 임베딩(4단계 PaP 후) + 패치 임베딩(3단계 Reprogramming 후)
- 고정된(Frozen) LLM 본체를 통과
Output Projection
- LLM의 마지막 출력 중 시계열 관련 부분만 평탄화(단일 1차원 벡터가 생성) 한 뒤, 선형 레이어를 통해 원하는 길이의 예측 벡터로 변환
- 즉, LLM의 추론 결과를 해석 가능한 예측값으로 변환하는 과정
4. EXPERIENTS
TIME-LLM에 관해 총 5가지 종류의 실험을 진행했는데요 각 실험에 대해 어떤 성능이 나왔는지 살펴보겠습니다!
4-1. LONG-TERM FORECASTING
4-2. SHORT-TERM FORECASTING
4-3. FEW-SHOT FORECASTING
4-4. ZERO-SHOT FORECASTING
4-5. Ablations
4-1. LONG-TERM FORECASTING
-> 장기 시계열 예측 성능 평가
-> 다양한 데이터 셋에서 여러 핫한 Transformer계열 / 딥러닝 계열 들과 비교했을때 SOTA 달성

- 과거 512 스텝의 데이터를 보고 미래의 24, 36, 48, 60, 96, 192, 336, 720 스텝 값 예측
- 사용 데이터셋: 장기 시계열 예측을 위한 표준 벤치마크 데이터셋인 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, ILI에서 수행
- 모델 백본(backbone): Llama-7B 모델
- 성능 평가 기준: 평균 제곱근 오차(Mean Square Error, MSE)와 평균 절대 오차(Mean Absolute Error, MAE)
4-2. SHORT-TERM FORECASTING
-> 단기 시계열 예측 성능 평가
-> 장기에 이어 단기 task에서도 SOTA 달성

- 미래의 6~48 스텝 값 예측
- 사용 데이터셋: 단기 예측을 위한 M4 벤치마크(The M4 Competition)
- 모델 백본(backbone): Llama-7B 모델
- 성능 평가 기준(행): 대칭 평균 절대 비율 오차 (SMAPE) , MASE (Mean Absolute Scaled Error), 전체 가중 평균 (OWA)
번외) 평가 기준 지표 설명



4-3. FEW-SHOT FORECASTING
-> 제한된 양의 훈련 데이터만을 사용하여 시계열 예측을 수행하는 능력
-> 10%, 5%의 제한된 데이터로 진행한 예측한 퓨샷task 에서도 대부분의 데이터셋에서 SOTA 달성
10%

5%

- 전체 훈련 데이터의 상위 10% 또는 5%만을 사용하여 모델을 학습
- 사용 데이터셋: 장기 시계열 예측을 위한 표준 벤치마크 데이터셋인 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, ILI에서 수행
- 모델 백본(backbone): Llama-7B 모델
- 성능 평가 기준: 평균 제곱근 오차(Mean Square Error, MSE)와 평균 절대 오차(Mean Absolute Error, MAE)
4-4. ZERO-SHOT FORECASTING
-> 학습 데이터를 전혀 보지 않고도 해당 작업을 수행하는 능력
-> 다른 데이터셋으로 학습한 후, 예측을 진행한 제로샷 task 능력도 출중함

- 학습 시 접하지 않은 다른 데이터셋(예: ETTh1에서 학습 후 ETTh2 예측)에 대해 예측을 수행
- 사용 데이터셋: 장기 시계열 예측을 위한 표준 벤치마크 데이터셋인 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, ILI에서 수행
- 모델 백본(backbone): Llama-7B 모델
- 성능 평가 기준: 평균 제곱근 오차(Mean Square Error, MSE)와 평균 절대 오차(Mean Absolute Error, MAE)
4-5. Ablations
a. Language Model Variants & Cross-modality Alignment
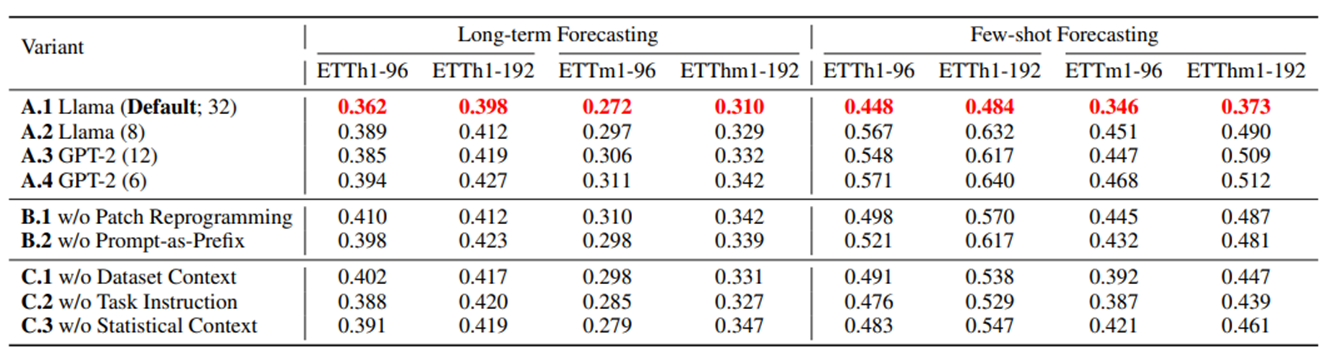
언어 모델 변형 (Language Model Variants): 다양한 용량 LLM(Llama와 GPT-2 등)을 비교
-> LLM의 크기가 클수록 TIME-LLM의 성능이 향상
모달리티 간 정렬 (Cross-modality Alignment) : Patch Reprogramming과 Prompt-as-Prefix기법의 효과를 분석
-> 이 두 구성 요소 중 하나라도 없을 경우 LLM이 시계열 예측을 효과적으로 수행하기 위한 지식 전달 능력이 저하
-> 즉, Patch Reprogramming과 Prompt-as-Prefix기법이 예측 성능에 효과적
-> Prompt-as-Prefix 내에서 입력 통계 정보(input statistics)를 제공하는 것이 성능에 가장 큰 영향
b. Reprogramming Interpretation

Figure 5 (a) ~ (d): Reprogramming(재프로그래밍) 학습 과정 시각화
- 에포크가 커질수록 특정 열(텍스트 프로토타입)과 행(패치)에서 강한 활성(밝은 색상)이 나타남
- 모델이 각 패치를 표현하는 데 특정 텍스트 프로토타입(단어 키워드)을 선택적으로 활용함

Figure 5 (e): 학습 후, 잘 최적화된 재프로그래밍 공간(d)의 예시
세로축: 잘게 나눈 시계열 데이터 조각(패치)
가로축: 시계열 패턴을 요약하는 단어 집합(텍스트 프로토타입)
진한 색: 해당 패치와 키워드가 잘 매칭됨(강한 관련성)
-> 준비된 많은 '언어 키워드(텍스트 프로토타입)' 중에서 실제로 대부분의 시계열 조각(패치)을 설명하는 데 '유용하게 쓰이는' 키워드는 소수

Figure 5 (f): 학습된 텍스트 프로토타입 시각화
-> 각 텍스트 프로토타입 벡터와 전체 단어 임베딩 간의 유사도를 계산
Word Set1, Word Set2 :"periodic", "seasonal", "quantile", "average"와 같이 시계열 데이터의 속성을 설명하는 데 유용한 단어들 관련성 높음 (진한색)
Word Set3:"outspoken", "galiee"와 같이 시계열과 관련이 적은 단어 관련성은 상대적으로 낮음(밝은색)
-> 즉, 학습을 통해 텍스트 프로토타입(시계열을 표현하는 단어집합, 상승/하락 등)을 잘 추출하고 있음을 시사
5. CONCLUSION
교차 모달리티 적응 (Cross-modality Adaptation) 방식의 TIME-LLM 제안
- 사전학습(Pre -Trained)된 LLM 기반 시계열 예측
- Model Reprogramming -> 시계열 데이터를 LLM이 이해하도록 변환
- Prompt-as-Prefix(PaP) -> 프롬프트를 통해 추론능력 강화
기존의 시계열 예측 전문 모델들을 능가하는 성능 달성, 특히 데이터가 부족한 Few-shot 및 Zero-shot 환경에서 뛰어난 결과
사전 학습된 대규모 언어 모델(LLM)의 가중치를 그대로 유지하면서(backbone) 시계열 예측 작업을 수행할 수 있음을 보임
그러나 LLM의 어떤 요소를 통해 시계열 예측이 잘 진행되는지에 대한 연구는 미비, 이에 대한 분석이 필요함
6. Example Code
Time-LLM 논문을 구현한 예시 코드를 통해 간단한 시계열 예측 task에 적용해봤습니다!
사용된 데이터셋: AirPassengers
https://www.kaggle.com/datasets/rakannimer/air-passengers
내용: 1949년부터 1960년까지의 월간 국제 항공 승객 수
형식: 월별(Monthly) 시계열 데이터
구조: 패널 형태로 구성된 데이터프레임
분할 방식: 마지막 12개월을 테스트 데이터로 사용
Time-LLM 구현 : neuralforecast 라이브러리
BackBone 모델 : GPT2
실험
1. 여러 시계열 모델 비교
2. TIME_LLM Prompt-as-Prefix (PaP) 방식 다르게 하며 비교
Time-LLM 예제는 다음 포스팅에서 리뷰해보도록 하겠습니다!
'Paper review' 카테고리의 다른 글
| [Paper review] PatchTST (0) | 2026.01.30 |
|---|---|
| [Paper review] GAN(Generative Adversarial Nets) (0) | 2026.01.29 |
| [Paper review] DLinear (0) | 2026.01.12 |
| [Paper review] Prophet 톺아보기 (0) | 2025.12.07 |
| [Paper review] A Comprehensive Survey of Deep Learning for Time Series Forecasting: Architectural Diversity and Open Challenges (0) | 2025.11.25 |



