

Hippo's data
[Paper review] PatchTST 본문
오늘은 PatchTST 모델이 제안된 논문을 리뷰해보도록 하겠습니다!
저번 리뷰에서 단순한 선형구조를 제안하여, “Transformer는 LTSF(Long term time-series Forecast)에 별로다” 라고 주장했던 Dlinear 관련 논문을 리뷰했었는데욥
이번에는 다시 " Transformer도 제대로 쓰면 선형 모델보다 훨씬 좋다" 라는 주장으로 해당 내용을 반박한 논문입니다!
Paper: A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS (Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam)
- Conference: ICLR 2023
- GitHub Repository: https://github.com/yuqinie98/PatchTST
- ArXiv: https://arxiv.org/abs/2211.14730
GitHub - yuqinie98/PatchTST: An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with
An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers." (ICLR 2023) https://arxiv.org/abs/2211.14730 - yuqinie98/PatchTST
github.com
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are serve
arxiv.org
→ 트랜스포머는 LTSF에 별로다 (LTSF-Linear (DLinear) 논문) 반박
→ 트랜스포머도 제대로 쓰면 선형 모델보다 훨씬 좋다 (Patch TST)
PatchTST = Patch Time Series Transform
= 패치단위(여러시점)로 처리 + 변수 독립적(Channel Independence)
제목 의미
A TIME SERIES IS WORTH 64 WORDS
→ 영미권 숙어 패러디: “A picture is worth a thousand words” (한 장의 그림이 천 마디 말의 가치가 있다)
→ 시계열에서 64개의 말( = 패치(Patch))이 가치가 있다
1. SUMMERIZE
| 항목 | 핵심 내용 |
| Problem | 기존 논문(Are Transformers Effective for Time Series Forecasting? - LTSF-Linear제안) 에서 LTSF에서 Transformer가 별로임을 주장 - 기존 Transformer는 Point-wise 방식(데이터 포인트 하나씩 입력)을 사용하여 로컬한 의미 정보를 잃고, 시퀀스 길이가 길어질수록 계산 복잡도가 기하급수적으로 증가 |
| Method | PatchTST (Patching + Transformer) • Patching: 단일 데이터 포인트보다는 일정 구간(Patch)으로 나눠 시계열의 의미단위 학습 • Channel Independence(CI): 각 변수를 별도의 샘플처럼 처리하여 하나의 인코더를 공유, 다변량 데이터에서 변수 간 상관관계를 억지로 학습하기보다 변수별로 독립적으로 학습하는 것이 더 일반화 성능이 좋음 |
| Results | LTSF-Linear를 포함한 모든 기존 SOTA 모델을 추월 특히 Look-back window가 길어질수록 성능이 훨씬 더 좋아짐 |
| Contribution | Transformer가 LTSF에서 효과적임을 재입증 시계열에서의 Self-supervised learning 가능성 제시 |
2. DETAIL
1. Introduction
- Transformer가 다양한 분야에서 성공을 거두며 시계열 분석에도 적용되고 있음
- 최근 연구(Are Transformers Effective for Time Series Forecasting?)에서 단순한 선형 모델(LTSF-Linear)이 더 좋은 성능을 보여주며 Transformer의 유용성에 의문을 제기
- PatchTST 기법 제안
- Patching (패칭): 시계열 데이터를 단일 시점(point-wise)이 아닌 하위 시계열 수준의 패치(patch)로 분할하여 입력 토큰으로 사용
- 계산 및 메모리 사용량 감소
- 더 긴 과거 기록(longer look-back window) 활용 능력 (실험증명)
- Channel-independence (채널 독립성): 다변량 시계열에서 각 채널(단일 변량 시계열)을 독립적으로 처리하여 모든채널에서 동일한 임베딩 및 Transformer 가중치를 공유
- 기존에는 channel-mixing 방식 다수
- self-supervised learning → representation learning, transfer learning 우수
- Patching (패칭): 시계열 데이터를 단일 시점(point-wise)이 아닌 하위 시계열 수준의 패치(patch)로 분할하여 입력 토큰으로 사용
2. RELATED WORK
- Patch in Transformer-based Models
- Transformer 기반 다양한 분야에서 Patch 기법이 유용하게 사용됨
- NLP - BERT, CV - VIT, Speech 등등
- Transformer-based Long-term Time Series Forecasting
- 기존 Attention 매커니즘에서 복잡도(complexity) 낮추기(n^2) + 예측 성능 향상 목적
- 대부분 아키텍처들 패치 중요성 무시(point-wise attention)
| 모델 | 주요 메커니즘 |
| LogTrans (Li et al., 2019) | 컨볼루션(convolutional) 기반 self-attention layer, LogSparse design |
| Informer (Zhou et al., 2021) | ProbSparse self-attention, distilling 기법 → 중요 key 추출 |
| Autoformer (Wu et al., 2021) | 전통 시계열 분석 기법에서 차용한 decomposition and auto-correlation 아이디어 → 수동적(handcrafted) 설계, semantic 정보 얻지X |
| FEDformer (Zhou et al., 2022) | 푸리에(Fourier) 기반 구조 → 선형 복잡도 |
| Pyraformer (Liu et al., 2022) | pyramidal attention module, intra-scale, inter-scale 연결 → 선형 복잡도 |
| Triformer (Cirstea et al., 2022) | patch attention 제안 → 단지 pseudo timestam를 쿼리로 사용하여 복잡도 줄임 → 패치 자체 입력단위X, semantic importance 포착X |
- Time Series Representation Learning
- 다양한 non-Transformer 기반 TS Representation Learning 제안됨
- Franceschi et al., 2019, Tonekaboni et al., 2021, Yang & Hong, 2022, Yue et al., 2022
- Transformer 기반 TS Representation Learning도 시도됨, 아직 잠재력 발휘되지 않음
- Time Series Transformer (TST) - Zerveas et al., 2021 , TS-TCC - Zerveas et al., 2021
- 다양한 non-Transformer 기반 TS Representation Learning 제안됨
3. PROPOSED METHOD
- look-back window L : (x1, ..., xL)
- forecast T future values : (xL+1, ..., xL+T )
- core architecture : vanilla Transformer encoder
3-1. MODEL STRUCTURE

- Forward Process
- Input: 다변량(Multivariate) 시계열
- Process: M개의 단변량(univariate) 시계열로 분리 → Transformer 백본에 개별적으로 독립적으로 입력 (모든 채널이 동일한 Transformer 가중치를 공유하며 학습 및 추론)
- Output: 각 단변량 시계열에 대해 독립적으로 예측
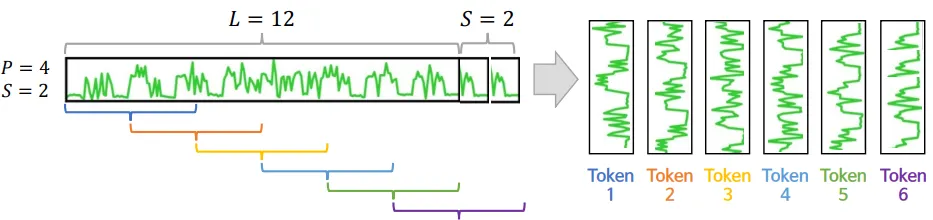
- Patching
- L: input 길이(look-back window)
- P: 패치 길이
- S: stride, 연속적 두 패치 사이의 겹치지 않는 영역의 길이(이동 길이)
- N: 패치 총 개수
- 마지막 패치를 만들기 위해(길이 맞추기 위함) 원본 시퀀스 끝에 S개만큼의 마지막 값을 반복하여 패딩(padding)
- $N = \left\lfloor \frac{L-P}{S} \right\rfloor + 2$
- 효과: 트랜스포머의 입력 토큰(input token) 수 감소
- 기존 트랜스포머 입력 토큰 수: L
- 패치 후, 입력 토큰 수: $N≈L/S$
- 연산 복잡도, 메모리 사용량 제곱(quadratically) 만큼 감소
- O(N^2) → O((L/S)^2)
DSBA - Paper Review 세미나 발표자료 참고
https://dsba.snu.ac.kr/seminar/?mod=document&uid=2670
[Paper Review] A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers
[ 발표 요약 ] 1. Topic A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers 2. Overview 이번 세미나 시간에는 ICLR 2023에 accept 된 long-term time series forecasting(LTSF) 방법론 PatchTST를 공유하고자 한다.
dsba.snu.ac.kr
- Transformer Encoder
- Transformer의 Multi-Head Attention 수행
- Loss Function
- MSE loss
- 각 시계열 채널(univariate series)에 대한 손실을 계산한 후, 모든 M개 시계열에 대해 평균하여 최종 손실을 구함

- Instance Normalization
- 각 단변량(univariate) 시계열을 독립적으로 정규화(평균0, 표준편차1)
- 정규화 후, 패치분할 → 모델 입력 → 원래 스케일 복원하여 출력
- 훈련, 테스트 데이터 간 분포 변화(distribution shift) 효과를 완화
3-2. REPRESENTATION LEARNING
Masked Autoencoder : 입력 시퀀스의 일부를 숨기고(마스크 처리), 모델은 숨겨진 내용을 복원하도록 학습
- 기존 연구 → 개별 시점(single time step) 마스킹
- A Transformer-based Framework for Multivariate Time Series Representation Learning (Zerveas et al., 2021)
- 인접한 시점의 값으로 보간하여 쉽게 유추가능
- 무작위 전략(randomization strategies)으로 해결시도
- 너무 많은 매개변수로 인해 학습 데이터가 부족할 때, 과적합되기 쉬움
- 각 time step(L)의 잠재 표현(D)을 미래 예측(T)과 채널 수(M)에 매핑→ 최종 출력 layer 매우 큰 파라미터 행렬(w) 필요 → w = (L·D) X (T·M)
- PatchTST → 패치(patch) 단위 마스킹
- 최종 출력 layer 재구성 → linear layer (D X P)
- 겹치지 않는(non-overlapping) 패치
- 마스킹 된 패치 정보가 다른 패치에 포함되지 않게
- 무작위 마스킹
- 마스킹된 패치 복원 학습시, MSE loss 최소화 학습
4. EXPERIMENTS
4-1. LONG-TERM TIME SERIES FORECASTING
- Datasets: 8개 (Weather, Traffic, Electricity, ETTh1, ETTh2, ETTm1, ETTm2)
- Weather, Traffic, Electricity → 대규모 데이터셋
- Baselines
- Transformer 기반 모델: Informer, Autoformer, FEDformer, Pyraformer, LogTrans
- non-Transformer 기반 모델: DLinear
- Experimental Settings
- 예측 길이
- ILI 데이터셋 : 24, 36, 48, 60
- 나머지: 96, 192, 336, 720
- Look-back Window (L)
- Transformer 기반 모델: 96
- non-Transformer 기반 모델(DLinear) : 336
- 이전 DLinear논문에서 언급 - Transformer 기반 모델 가장 성능 좋았던 길이
- 예측 길이
- Model Variants: 2가지 버전 PatchTST
- PatchTST/64 - Input patch(64), L(512)
- PatchTST/42 - Input patch(42), L(336)
- Results
- PatchTST 모델이 Baselines(Transformer 기반 및 DLinear)에 비해 우수한 성능
- 최고 성능의 Transformer 기반 모델 비교
- PatchTST/64는 MSE에서 21.0%, MAE에서 16.7%의 전반적인 감소
- PatchTST/42는 MSE에서 20.2%, MAE에서 16.4%의 감소
- DLinear 비교
- 특히 큰 데이터셋(Weather, Traffic, Electricity)에서 성능차이 큼
- 최고 성능의 Transformer 기반 모델 비교
- PatchTST 모델이 Baselines(Transformer 기반 및 DLinear)에 비해 우수한 성능
4-2. REPRESENTATION LEARNING
- experimental Settings
- 자기지도, 사전 학습(Self-supervised Pre-training)
- non-overlapped patch
- Look-back Window (L): 512
- 패치 길이(P): 12 (총 42개의 패치 생성)
- 마스킹 비율(Masking ratio): 40%
- 100 epoch self-supervised pre-training
- Evaluation → 사전 학습 후, 평가 위해 2가지 방식 이용하여 지도학습(Supervised Learning) 수행
- Linear Probing - 마지막 레이어(모델 Head)만 20 Epoch 학습 (다른 부분은 freezing)
- vs supervised → Pre-training에 따른 representation learning 능력 비교
- End-to-end Fine-tuning
- vs Linear Probing → Fine-tuning 차이(전체 vs 일부) 능력 비교
- Linear Probing 10 epoch → 마지막 레이어(모델 Head)만 10 Epoch 학습 (다른 부분은 freezing)
- 전체 20 Epoch 학습
- Linear Probing - 마지막 레이어(모델 Head)만 20 Epoch 학습 (다른 부분은 freezing)
- 자기지도, 사전 학습(Self-supervised Pre-training)
- Results
- Comparison with Supervised Methods
- Self-supervised(Fine-tuning vs Linear Probing) vs Supervised
- 큰 데이터셋 대상(Weather, Traffic, Electricity)
- Self-supervised Pre-training이 효과적 → representation learning 효과 확인
- Fine-tuning > Supervised
- PatchTST의 우수한 효과
- 다른 트랜스포머 기반 모델들보다 뛰어난 성능
- Transfer Learning
- pre-trained: Electricity 데이터셋
- fine-tuning: Weather, Traffic 데이터셋
- PatchTST가 baselines(Transformer 기반 모델) 보다 우수한 성능
- Comparison with Other Self-supervised Method
- PatchTST self-supervised learning 성능과 다른 time-series representation learning 모델과 비교
- time-series representation learning 모델: BTSF, TS2Vec, TNC, TS-TCC
- 데이터셋: ETTh1
- Self-supervised, Transferred 둘다 PatchTST가 다른 representation learning 모델보다 우수
- PatchTST self-supervised learning 성능과 다른 time-series representation learning 모델과 비교
4-3. ABLATION STUDY
- Patching and Channel-independence
- PatchTST vs FEDformer(기존 Transformer 기반 모델 중 SOTA모델)
- FEDformer → channel-mixing(변수간 상관성 고려)
- 비교 PatchTST( P+CI / P / CI / Original) / FEDformer
- P(Patching ), CI(Channel-independence) 둘다 적용한 PatchTST가 가장 우수한 성능
- Patching, Channel-independence 기법의 우수성 입증
- PatchTST vs FEDformer(기존 Transformer 기반 모델 중 SOTA모델)
- Varying Look-back Window
- 기존 논문 : 기존 Transformer 기반 LTSF 모델들은 더 긴 look-back window(L)의 이점을 제대로 활용하지 못함
- Transformer 기반 모델들은 큰 크기의 look-back window에서 오히려 성능이 하락하여 temporal relation을 잘 추출하지 못하는 경향
- look-back window(L)이 길어질수록 MSE 감소
- PatchTST가 긴 과거 시퀀스로부터 temporal relation 효과적 추출, 예측 성능 향상
- 기존 논문 : 기존 Transformer 기반 LTSF 모델들은 더 긴 look-back window(L)의 이점을 제대로 활용하지 못함
4-4. Appendex
- CHANNEL-INDEPENDENCE ANALYSIS
- Channel-Independence vs Channel-Mixing
- Adaptability: Channel-Independence → 각 채널이 자신에게 적합한 어텐션 맵(attention map) 학습 (유사한 패턴이라도 다른 어텐션맵 특징 시각화)
- Channel-Mixing 모델은 오버피팅 현상 발생 → Channel-Independence의 더 좋은 일반화 능력
- Channel-Independence vs Channel-Mixing
5. CONCLUSION AND FUTURE WORK
- 시계열 예측 위한 Transformer 구조 제안 (PatchTST)
- 핵심 기법: 패칭(patching), channel-independent(CI)
- 우수한 성능
- Supervised Learning - 기존 Transformer 기반 모델들 보다 우수
- Self-supervised Learning
- Transfer Learning
3. Implementation
https://github.com/yuqinie98/PatchTST?tab=readme-ov-file
GitHub - yuqinie98/PatchTST: An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with
An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers." (ICLR 2023) https://arxiv.org/abs/2211.14730 - yuqinie98/PatchTST
github.com
- 예시 데이터셋을 이용하여 실험
- Supervised Learning Transformer 후 예측
- Self-supervised Learning Transformer → 전체 파인튜닝 후 예측
4. Discussion
- 현재 PatchTST모델 → Channel Independence 방식
- 직관적으로 변수간 상관성이 모델 예측에 중요할 것이라고 생각됨
- channel-mixing으로 성능 끌어올린 방법론이 있는지
- 각 패치 길이를 동일하게 설정함
- 패치(P)와 스트라이드(S) 길이를 동적으로 변경해서 모델에 반영한다면?
- 변동이 큰 시퀀스 부분은 패치길이를 짧게? / 주기성과 유사하게 패치개수만큼 분할 등
- 시계열 학습 불알정할 가능성 매우 큼 Like GAN idea 유사
- EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting
- (CIKM 2025)
- 시계열의 엔트로피 변화를 감지해 Patch를 자동으로 조절하는 모델
- https://arxiv.org/html/2509.26157v1
- 변동이 큰 시퀀스 부분은 패치길이를 짧게? / 주기성과 유사하게 패치개수만큼 분할 등
- 패치(P)와 스트라이드(S) 길이를 동적으로 변경해서 모델에 반영한다면?
- PatchTST + 변수 상관관계까지 고려(Channel Attention 레이어) = CT-PatchTST (Channel-Time PatchTST
- https://arxiv.org/abs/2501.08620
EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting
EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting Sachith Abeywickrama1, 2 Emadeldeen Eldele3, 2 Min Wu2 Xiaoli Li2, 4 Chau Yuen1 1School of Electrical and Electronics Engineering, Nanyang Technological University, Singa
arxiv.org
CT-PatchTST: Channel-Time Patch Time-Series Transformer for Long-Term Renewable Energy Forecasting
Accurate forecasting of renewable energy generation is fundamental to enhancing the dynamic performance of modern power grids, especially under high renewable penetration. This paper presents Channel-Time Patch Time-Series Transformer (CT-PatchTST), a nove
arxiv.org
- 현재 PatchTST모델 → Channel Independence 방식
- 직관적으로 변수간 상관성이 모델 예측에 중요할 것이라고 생각됨
- channel-mixing으로 성능 끌어올린 방법론이 있는지
- 각 패치 길이를 동일하게 설정
- 패치(P)와 스트라이드(S) 길이를 동적으로 변경해서 모델에 반영한다면?
- 변동이 큰 시퀀스 부분은 패치길이를 짧게? / 주기성과 유사하게 패치개수만큼 분할 등
- 시계열 학습 불알정할 가능성 매우 큼 Like GAN idea 유사
- EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting
- (CIKM 2025)
- 시계열의 엔트로피 변화를 감지해 Patch를 자동으로 조절하는 모델
- https://arxiv.org/html/2509.26157v1
- 변동이 큰 시퀀스 부분은 패치길이를 짧게? / 주기성과 유사하게 패치개수만큼 분할 등
- 패치(P)와 스트라이드(S) 길이를 동적으로 변경해서 모델에 반영한다면?
- PatchTST + 변수 상관관계까지 고려(Channel Attention 레이어) = CT-PatchTST (Channel-Time PatchTST)
- https://arxiv.org/abs/2501.08620
EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting
EntroPE: Entropy-Guided Dynamic Patch Encoder for Time Series Forecasting Sachith Abeywickrama1, 2 Emadeldeen Eldele3, 2 Min Wu2 Xiaoli Li2, 4 Chau Yuen1 1School of Electrical and Electronics Engineering, Nanyang Technological University, Singa
arxiv.org
CT-PatchTST: Channel-Time Patch Time-Series Transformer for Long-Term Renewable Energy Forecasting
Accurate forecasting of renewable energy generation is fundamental to enhancing the dynamic performance of modern power grids, especially under high renewable penetration. This paper presents Channel-Time Patch Time-Series Transformer (CT-PatchTST), a nove
arxiv.org
'Paper review' 카테고리의 다른 글
| [Paper review] GAN(Generative Adversarial Nets) (0) | 2026.01.29 |
|---|---|
| [Paper review] DLinear (0) | 2026.01.12 |
| [Paper review] Prophet 톺아보기 (0) | 2025.12.07 |
| [Paper review] A Comprehensive Survey of Deep Learning for Time Series Forecasting: Architectural Diversity and Open Challenges (0) | 2025.11.25 |
| [Paper review] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models (10) | 2025.07.16 |



